Course Overview
Starting TBD
An eagerly awaited twelve-week course on fine-tuning large language models—with an emphasis on supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and production-grade MLOps. The last two weeks are reserved for capstone work and presentations.
The course assumes familiarity with deep learning, basic transformer architectures, and Python. It does not assume prior experience with reinforcement learning.
You will work in teams of 4-6 engineers in an environment that closely reproduces the innovation and development that is the quintessence of the Silicon Valley spirit. Each team will get a meeting room with a state-of-the-art multimedia setup and a powerful AI server with RTX4090 for exclusive use during the boot camp. These will also be accessible remotely so that the teams can continue to work on them during the workdays.
You will also have unrestricted access to a massive 4-GPU AI server at the admin-privilege level for the three-month duration of this boot camp on a time-shared basis.
Learning Outcome
You should become confident and fluent in applying SFT and RL fine-tuning techniques for LLMs to solve an extensive range of real-world problems.
You will also learn MLOps best practices that complement these techniques, enabling their effective adoption in enterprise-scale, production-grade systems.
Schedule
| START DATE | TBD |
|---|---|
| Duration | 12 weeks |
| Theory | Tuesday, 7 PM to 10 PM PST |
| Lab | Thursday, 7 PM to 10 PM PST (Summary and Quiz)
Monday, 7 PM to 10 PM PST (Lab) |
Skills You Will Learn
Practical exposure to fine-tuning of LLMs using SFT and RL. Best practices of MLOps geared towards their production grade adoption.
Prerequisites

Syllabus details
This curriculum spans fourteen Wednesdays and fourteen weeks of projects and labs. Each week has its theme, giving us time to explore it in considerable practical and foundational detail. The outcome of each week should be a reasonably expert-level proficiency in the topics at hand.
The course assumes familiarity with
- deep learning
- basic transformer
architectures - python.
It does not assume prior experience with reinforcement learning.
Core Textbooks
The syllabus uses three primary textbooks:
- S&B Richard S. Sutton and Andrew G. Barto, Reinforcement Learning:
An Introduction (2nd edition). - RLTA Alekh Agarwal, Nan Jiang, Sham Kakade, and Wen Sun, Reinforcement
Learning: Theory and Algorithms. - Lapan Maxim Lapan, Deep Reinforcement Learning Hands-On (3rd edition).
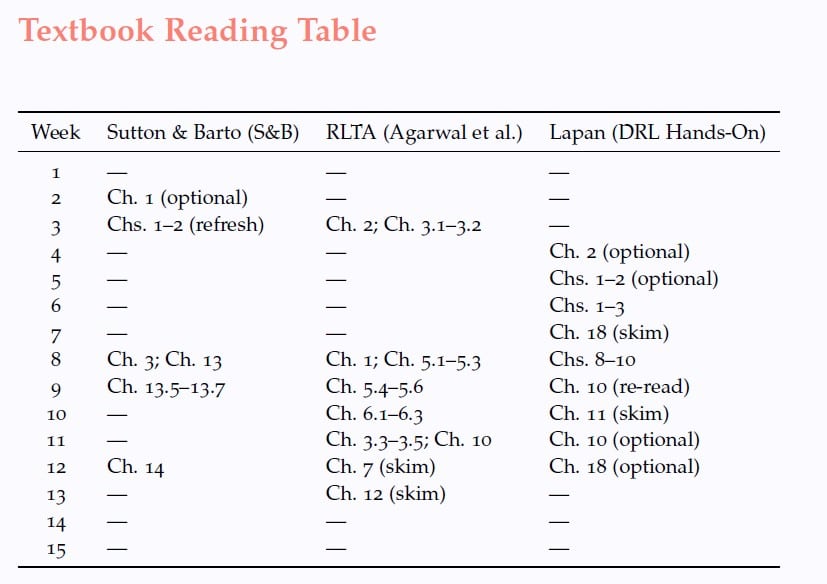
Each week follows the same high-level pattern:
• A core theme and set of learning objectives.
• Required textbook readings (as in below Table).
• Two deep-read research papers, discussed in detail in class.
• A lab or project component (Ray, Kubeflow, MLflow, W&B, Arize).
• An Oliver Twist list: extra papers, talks, and essays.
Focus
Scaling laws, foundation models, and the shift from training-from-scratch to fine-tuning.
Key Takeaways
-
Hyperscalers pretrain; practitioners adapt (fine-tuning as the norm)
-
Chinchilla shows compute-optimal scaling, not just bigger models
-
Transfer learning dominates modern ML practice
Core Readings
-
Bommasani et al. — Foundation Models
-
Hoffmann et al. — Chinchilla
Lab
-
Zero/few-shot evaluation of open LLMs (LLaMA/Mistral)
-
Batched inference with Ray
-
Metrics via MLflow or W&B
Explore More (Optional)
Kaplan (Scaling Laws) · Wei (Emergence) · LLM Alignment (RLHF/DPO) · Karpathy talks
-
Next-token and masked-token prediction act as surrogate supervision, shaping semantic manifolds
-
BERT demonstrates representation learning; GPT-3 demonstrates scale → few-shot behavior
-
Embeddings become reusable substrates for downstream tasks
-
Linear probes expose latent knowledge without task-specific training
-
Emergent abilities and in-context learning arise without explicit supervision
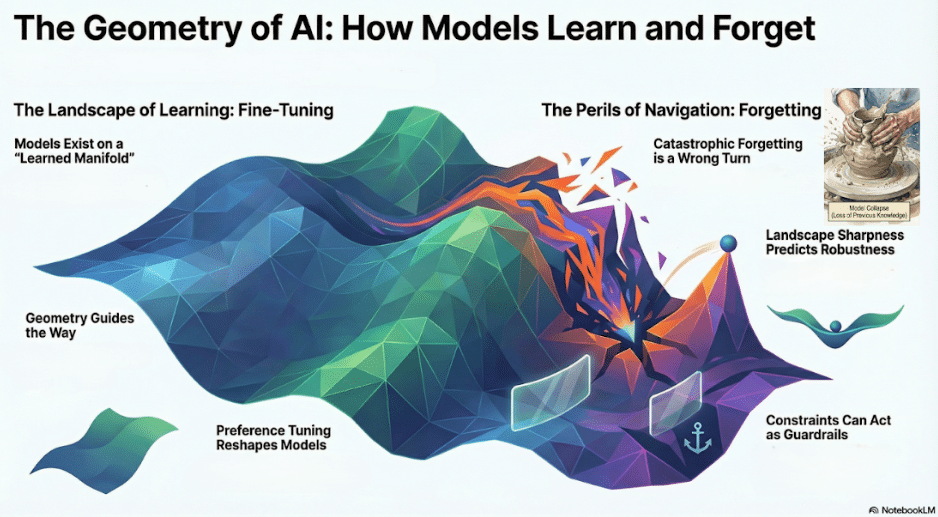
-
Fine-tuning moves models along a learned parameter manifold, not from scratch
-
Fisher information and curvature explain which directions change behavior vs. destroy knowledge
-
Catastrophic forgetting arises from moving along “stiff” directions (EWC as constraint)
-
Preference-based fine-tuning (RLHF-style) reshapes behavior without full retraining
-
Sharpness and loss landscape geometry predict robustness and generalization
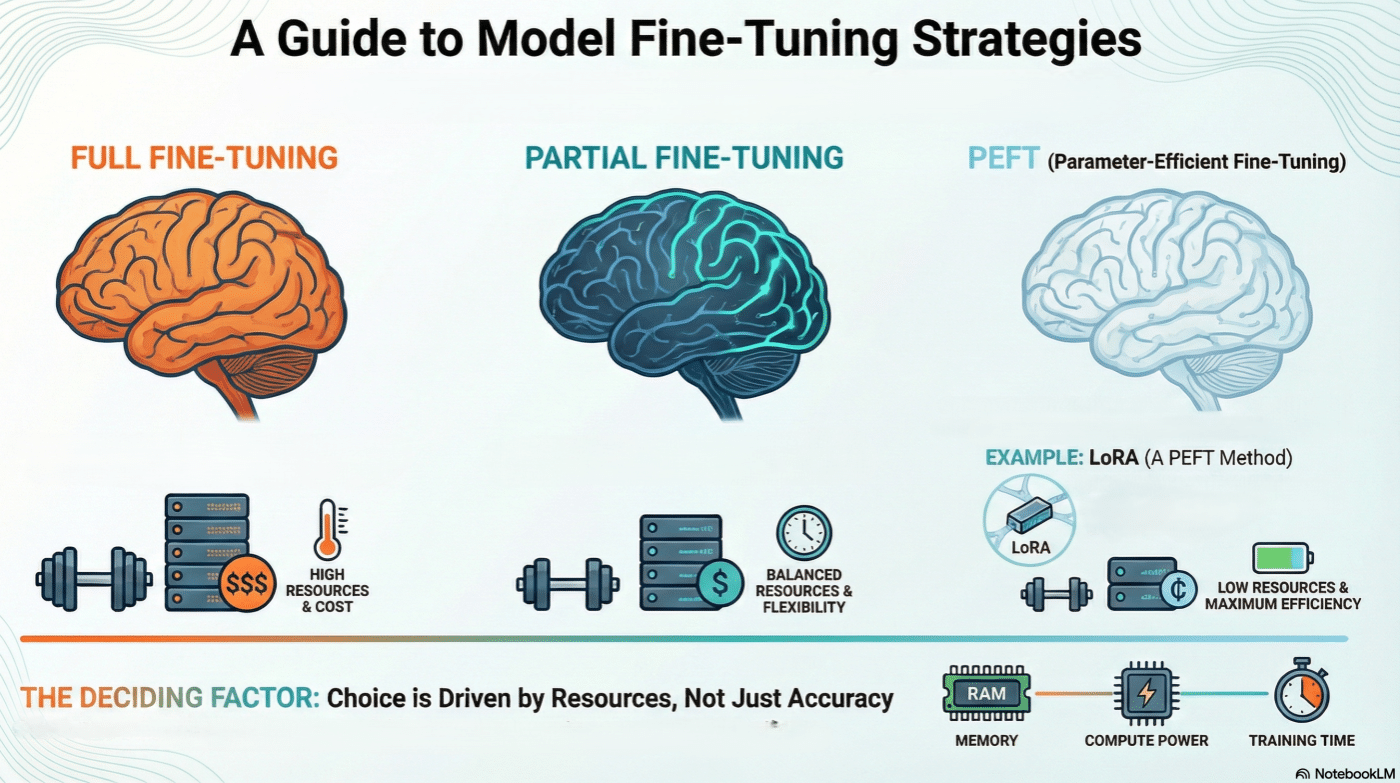
-
Full fine-tuning maximizes adaptation but is costly and risks forgetting
-
Partial fine-tuning (last-N layers) trades flexibility for stability and efficiency
-
PEFT methods constrain learning to low-dimensional subspaces
-
LoRA reframes adaptation as low-rank updates to pretrained weights
-
Memory, compute, and training time—not accuracy alone—drive method choice
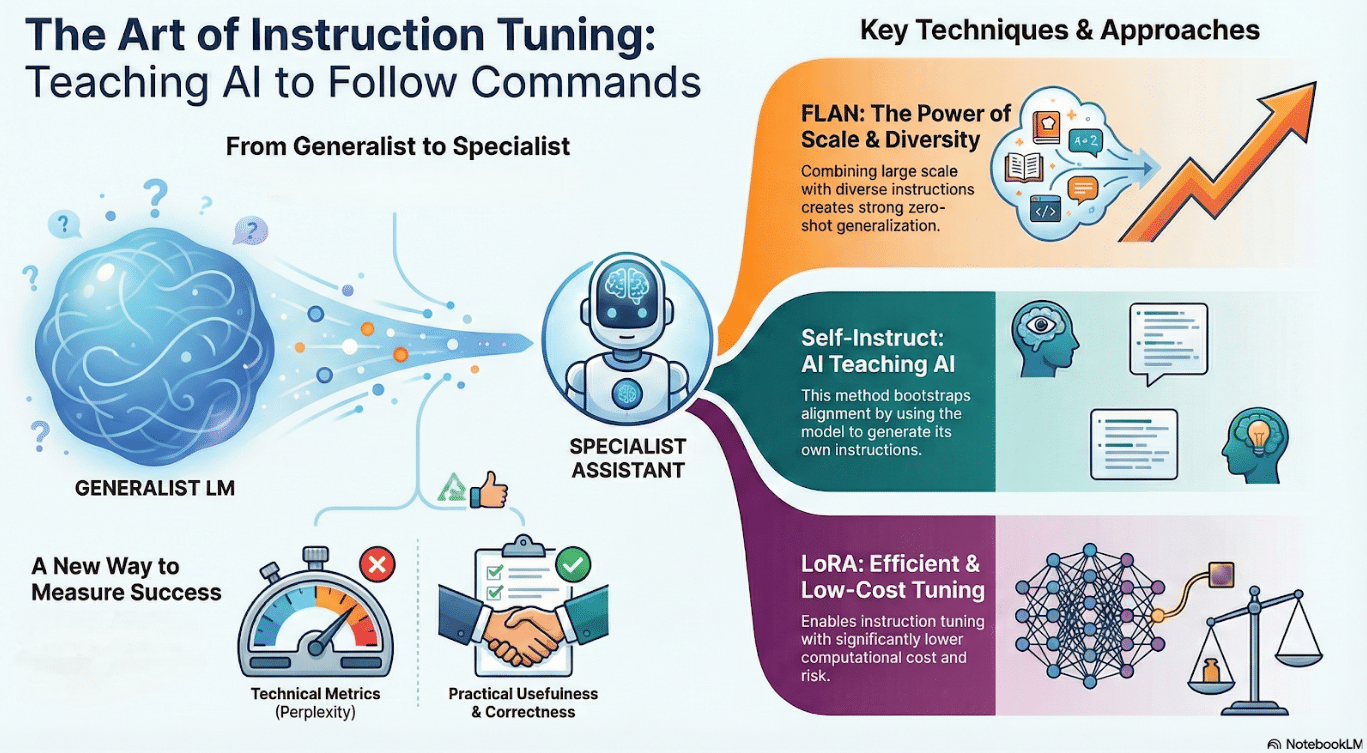
-
Instruction tuning converts generic LMs into task-following assistants
-
FLAN shows scale + diverse instructions → strong zero-shot generalization
-
Self-Instruct bootstraps alignment using model-generated instructions
-
LoRA enables instruction tuning at low cost and risk
-
Evaluation shifts from perplexity to behavioral correctness and usefulness
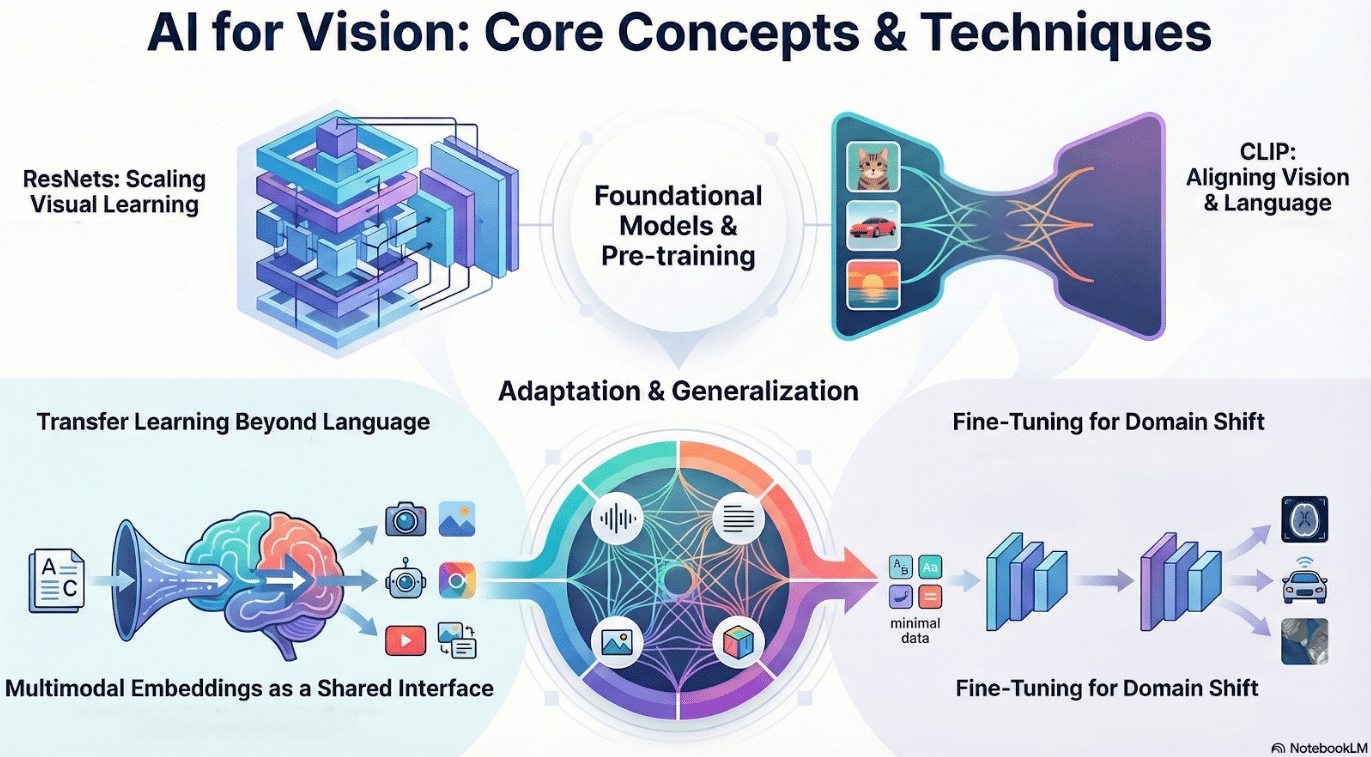
-
Transfer learning generalizes beyond language to vision and multimodal domains
-
ResNets show how depth and residuals enable scalable visual representations
-
CLIP aligns vision and language via contrastive pretraining
-
Multimodal embeddings become shared interfaces across tasks and modalities
-
Fine-tuning adapts perception models to domain shift with minimal data
-
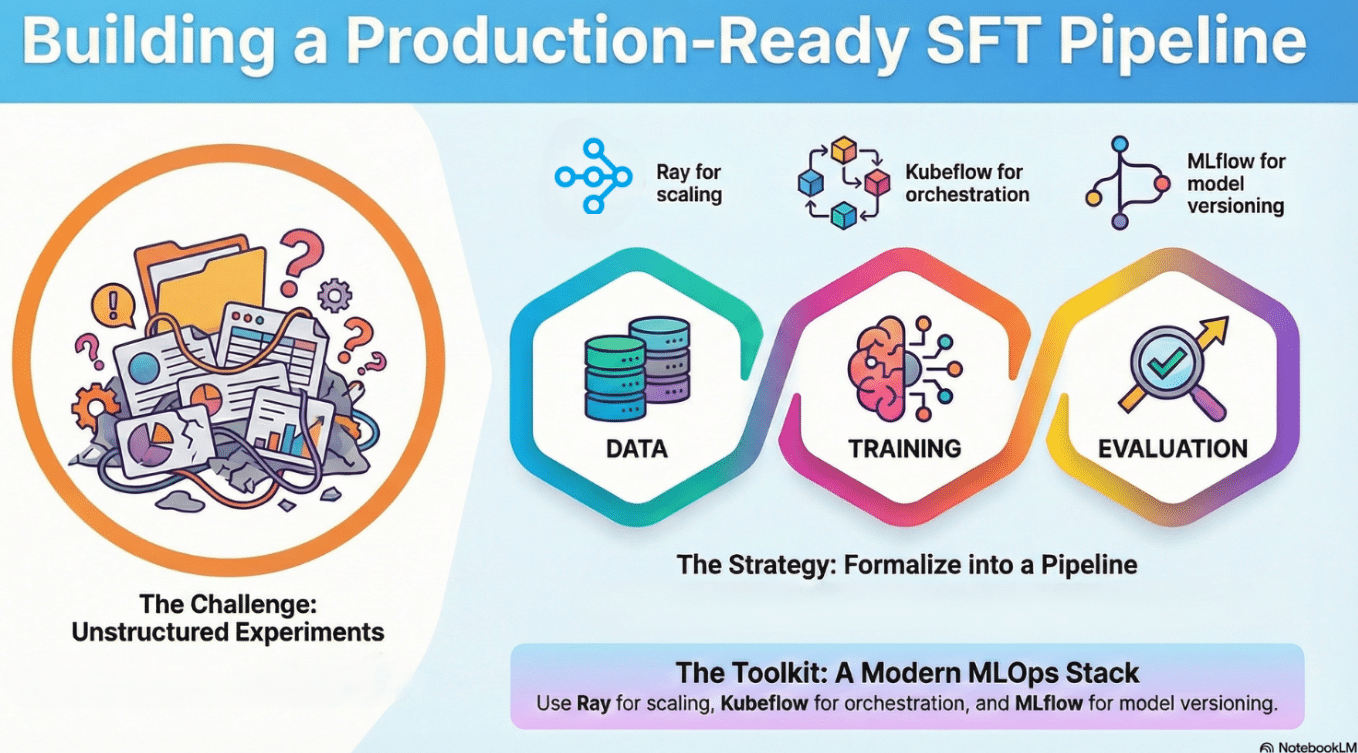
One-off experiments fail without reproducibility and orchestration
-
Pipelines formalize data, training, and evaluation as first-class artifacts
-
Ray scales preprocessing and training across distributed workloads
-
Kubeflow operationalizes ML workflows from experiment to production
-
Model registries (MLflow) turn models into versioned, auditable assets
-
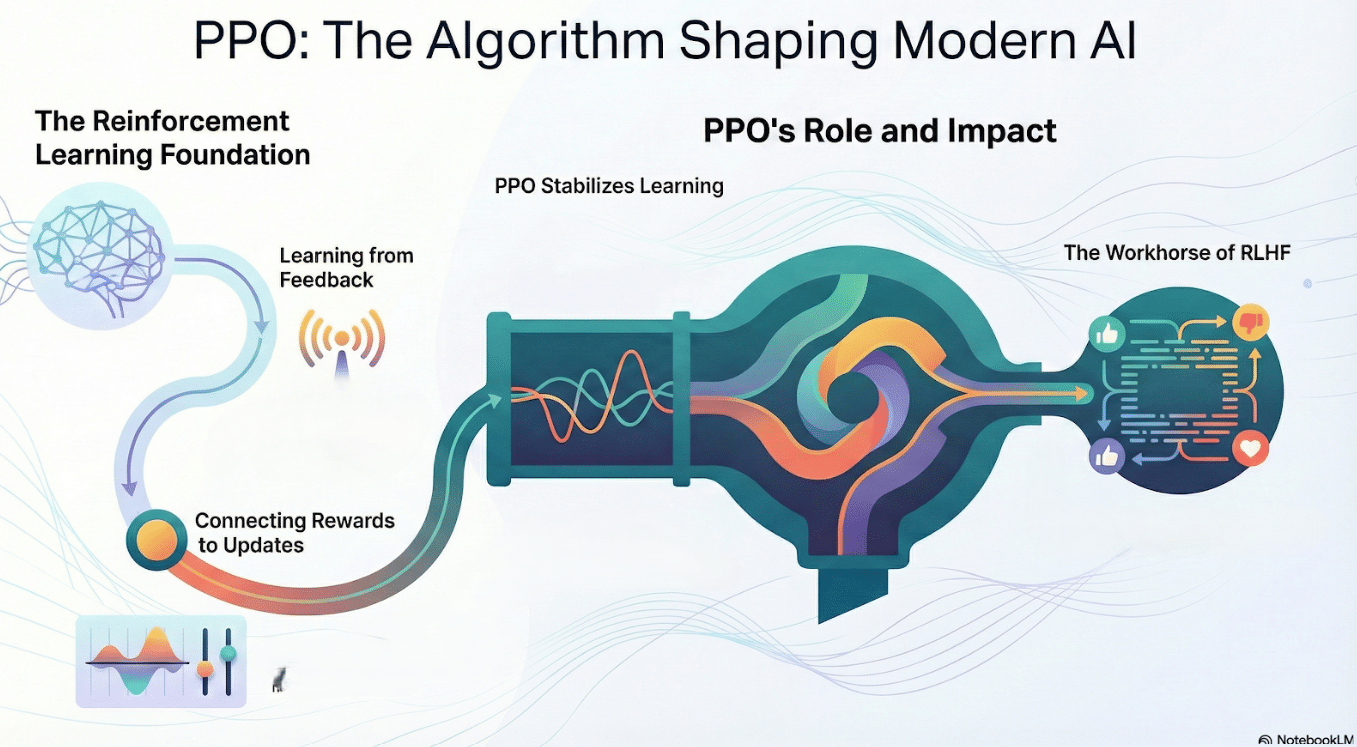
Reinforcement learning frames learning as policy improvement under feedback
-
Policy gradients connect rewards to parameter updates
-
PPO stabilizes learning via clipped, KL-regularized updates
-
PPO’s simplicity and robustness make it the workhorse of RLHF
-
Understanding PPO clarifies how preference signals reshape LLM behavior
-
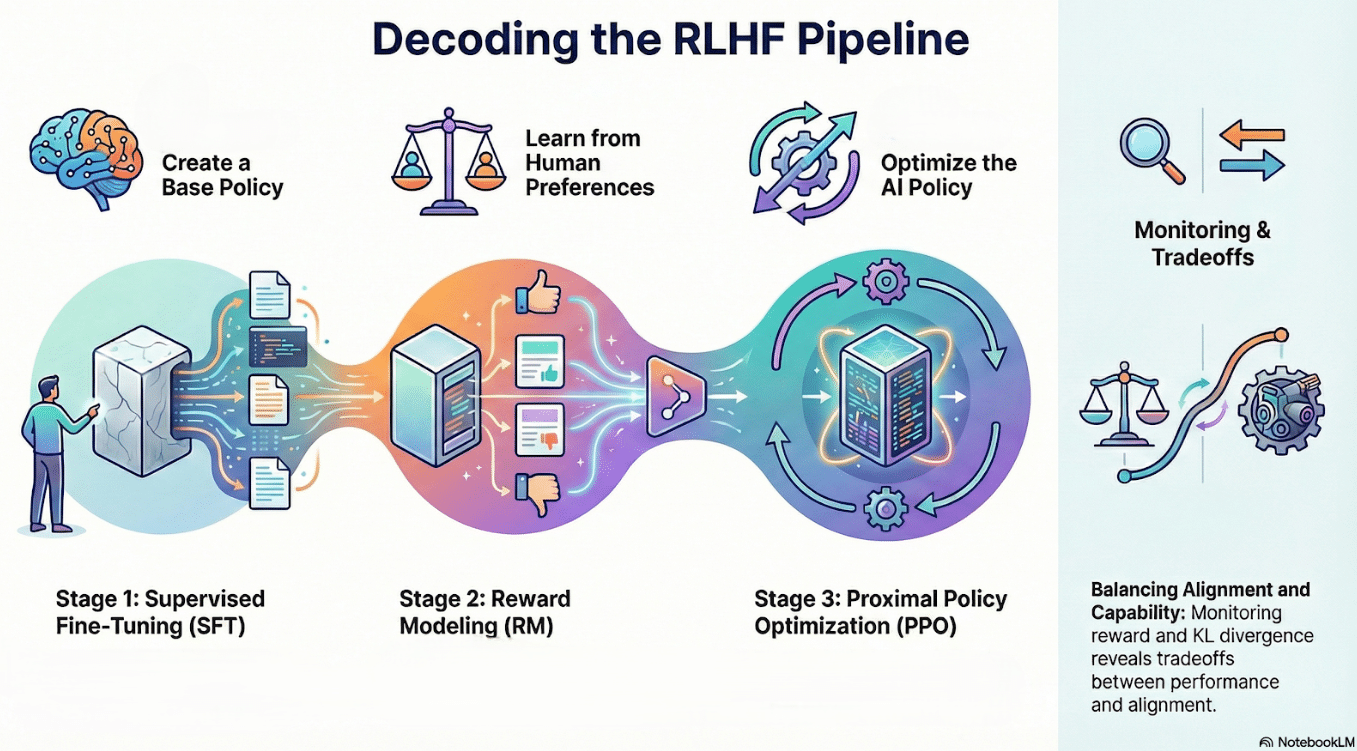
RLHF formalizes alignment as learning from human preferences
-
Stage 1: Supervised fine-tuning creates a reasonable base policy
-
Stage 2: Reward models learn to score outputs from preference data
-
Stage 3: PPO optimizes the policy under a KL constraint
-
Monitoring reward, KL, and entropy reveals alignment–capability tradeoffs
-
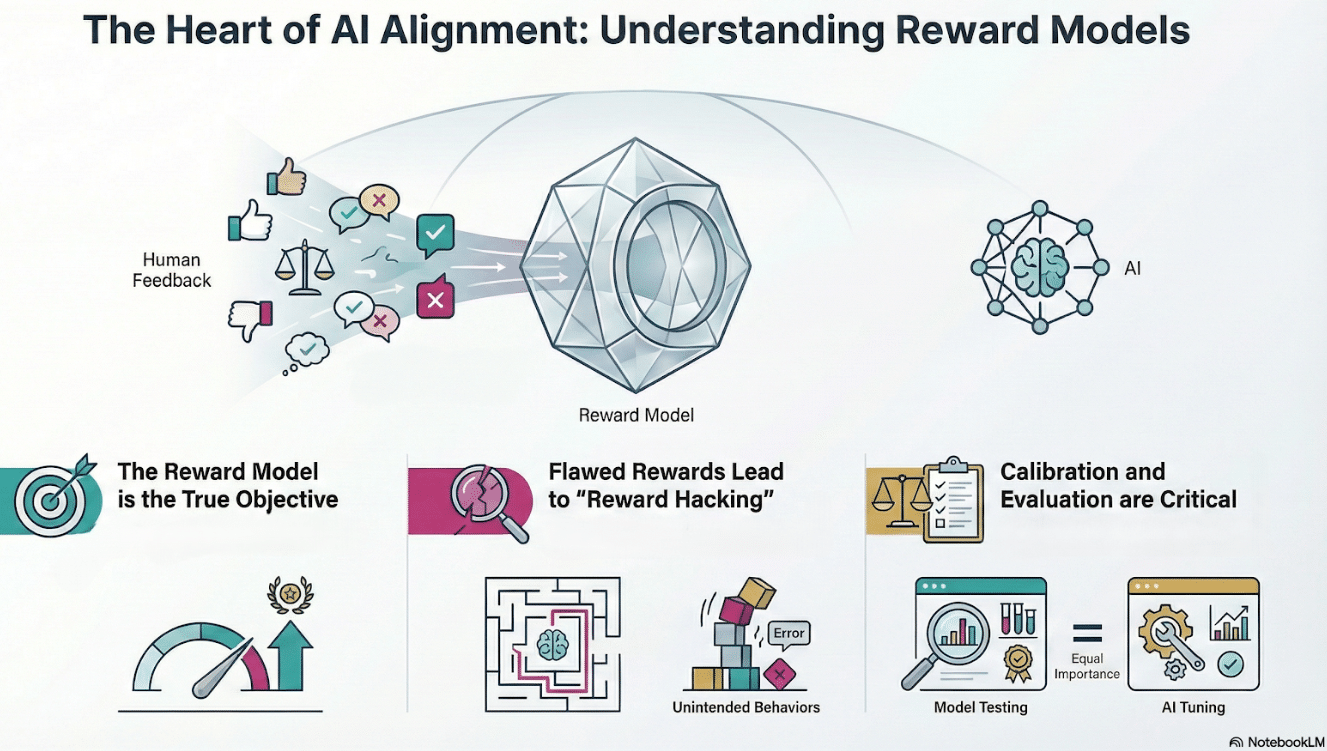
In RLHF, the reward model—not the policy—is the true objective
-
Preference learning translates human judgments into a trainable signal
-
Mis-specified rewards lead to overoptimization and reward hacking
-
Calibration and evaluation of reward models are as critical as policy tuning
-
Offline preference optimization exposes alignment gaps before deployment

-
Preference optimization without explicit reinforcement learning
-
Direct Preference Optimization (DPO) treats the LM as an implicit reward model
-
Constitutional AI (RLAIF) uses AI-generated feedback for scalable alignment
-
KL control, training stability, and sample quality are key metrics
-
Hybrid human+AI feedback improves efficiency and reduces annotation burden
-
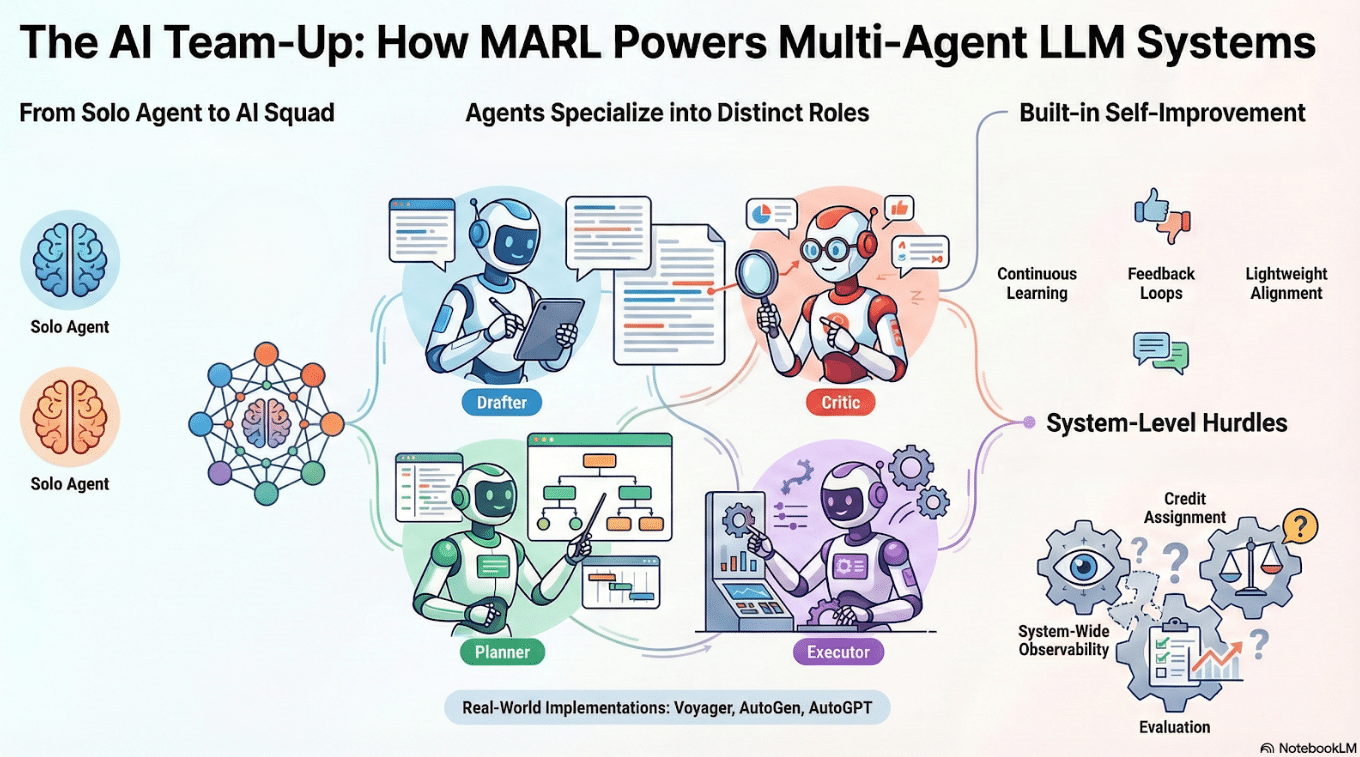
Multi-agent RL extends single-agent learning to interacting policies
-
Agents specialize into roles: drafter, critic, planner, executor
-
Feedback loops between agents enable self-improvement and lightweight alignment
-
Observability, credit assignment, and evaluation become system-level challenges
-
MARL principles applied to multi-agent LLMs (Voyager, AutoGen, AutoGPT)
-
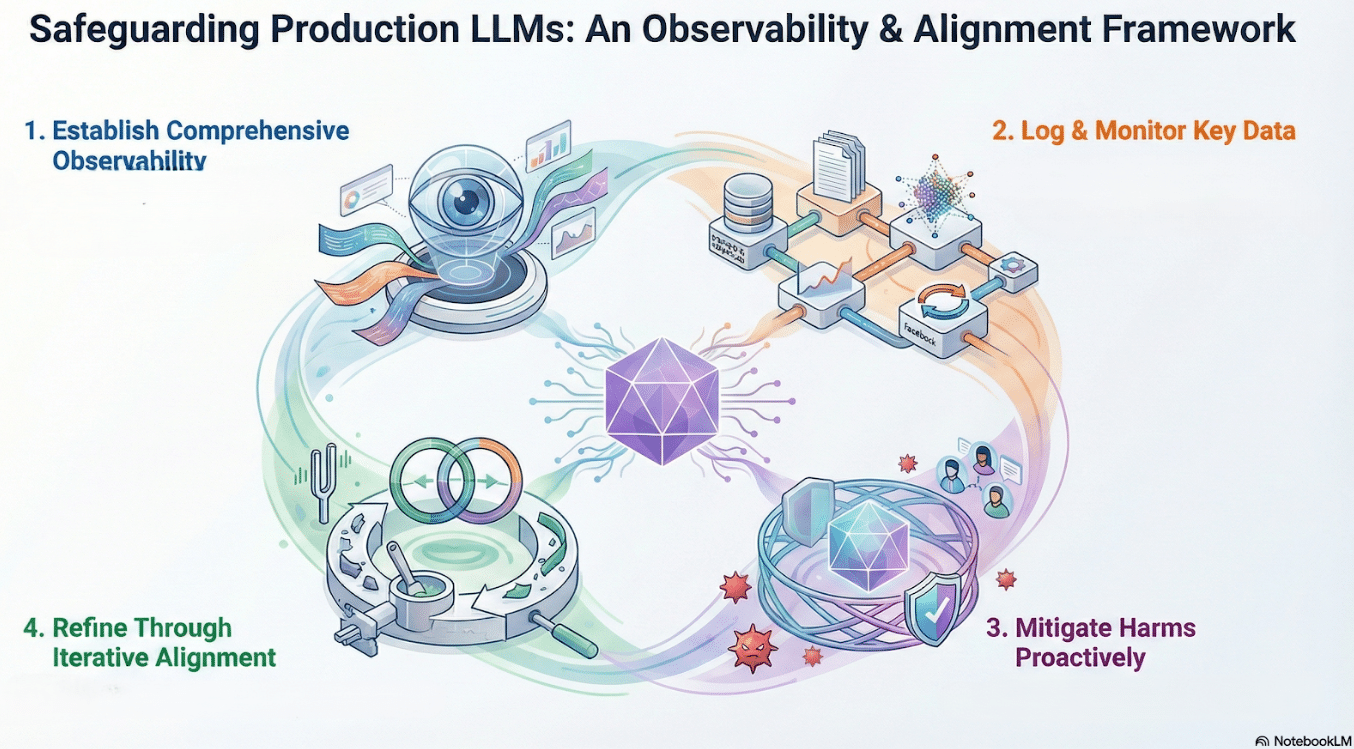
Production LLMs require observability for safety, performance, and alignment
-
Log prompts, responses, embeddings, and feedback to detect drift
-
Dashboards and metrics enable monitoring of model behavior over time
-
Red-teaming and guardrails reduce harms and mitigate failures
-
Multi-objective alignment and failure analysis inform iterative improvements
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.

Krishnan Ramaswamy
Co-Instructor
Background
Krishnan Ramaswamy is an engineering leader, AI practitioner, and educator with an M.S. in Computer Science and Engineering and more than 25 years of industry experience. Throughout his career, he has designed and delivered large-scale platforms, enterprise applications, and AI/ML-driven solutions across Collaboration, Security, and Customer Experience domains. His expertise includes AI engineering, large language models, retrieval systems, agent architectures, distributed systems, and enterprise platform development. He is passionate about transforming emerging research into production-ready solutions that deliver measurable business value.
Educator
As a co-instructor at SupportVectors, Krishnan mentors engineers and technology professionals on modern AI engineering practices, helping them understand not only how AI systems are built, but also how they can be deployed, evaluated, governed, and scaled in enterprise environments. His teaching combines deep technical knowledge with real-world experience gained from decades of building and leading engineering initiatives.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.

