Course Overview
Starting on Saturday, June 6, 2026
This is the eagerly awaited 12-week bootcamp designed to deep dive into the world of Large Language Models (LLMs) and Retrieval Augmented Generation (RAG). This course bridges foundational machine learning theories with enterprise-scale engineering practices..
You will work in teams of 4–6 engineers in an environment that reflects the innovation-driven spirit of Silicon Valley. Participants will have access to a state-of-the-art AI training datacenter featuring 20+ GPU servers and 40+ NVIDIA GPUs, including RTX PRO 6000 Blackwell, RTX 5090, and RTX 4090 systems.
The infrastructure will be available throughout the boot camp for hands-on training, experimentation, model development, and collaborative AI projects, with both on-site and remote access support.
Learning Outcome
You should become confident and fluent in applying LLMs to solve an extensive range of real-world problems, and develop theoretical and hands-on expertise in Retrieval-Augmented Generation (RAG) techniques and AI Search.
Practical exposure to vector embeddings, semantic AI search, retrieval-augment generation, multi-modal learning, video comprehension, adversarial attacks, computer vision, audio-processing, natural language processing, tabular data, anomaly and fraud detection, healthcare applications, techniques of prompt engineering
Schedule
| START DATE | SATURDAY, June 6, 2026 |
|---|---|
| Periodicity | Meet every Saturday for twelve weeks |
| Schedule | From 11 AM to 5 PM PST |
| Morning Session | 11 AM to 1 PM PST |
| Lunch Served | 1 PM to 1:30 PM PST |
| Afternoon Session | 1:30 PM to 4 PM PST |
| Project Presentations | 4 PM to 5 PM |
| Lab Walkthrough | Monday, 7 PM to 10 PM Wednesday, 7 PM to 10 PM |
| Summary & Quiz | Tuesday, 8.30 AM to 10 AM |
| Clinic Hours | Thursday, 8.30 AM to 10 AM |
Skills You Will Learn
Practical exposure to vector embeddings, semantic AI search, retrieval-augment generation, multi-modal learning, video comprehension, adversarial attacks, computer vision, audio-processing, natural language processing, tabular data, anomaly and fraud detection, healthcare applications, techniques of prompt engineering, core knowledge of Retrieval-Augmented Generation (RAG) and AI Search.
Prerequisites
Syllabus details
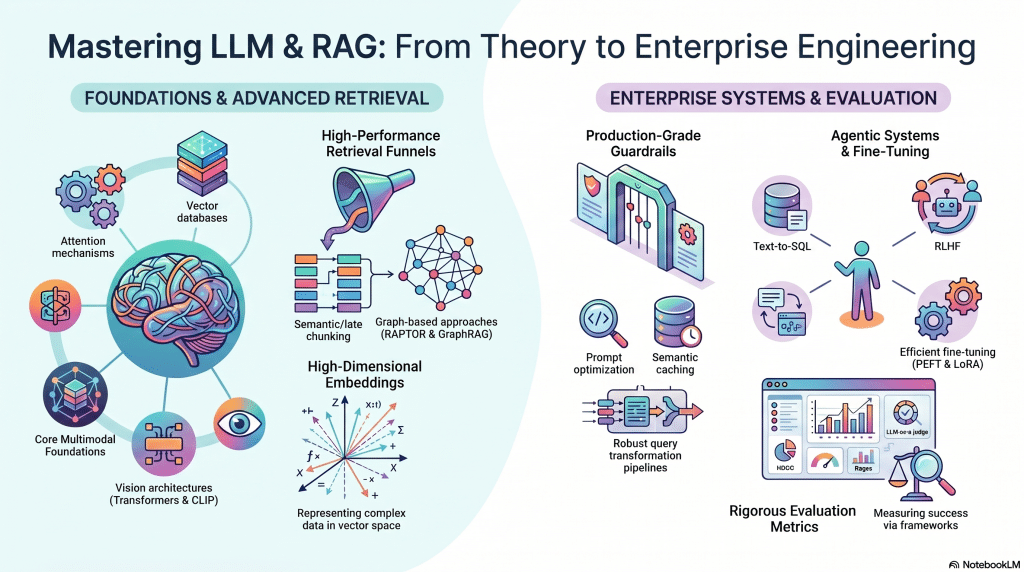
Focus
A 12-week bootcamp designed to deep dive into the world of Large Language Models (LLMs) and Retrieval Augmented Generation (RAG). This course bridges foundational machine learning theories with enterprise-scale engineering practices.
What Will Be Covered
- Foundations & Multimodality: Attention mechanisms, vector databases, high-dimensional embeddings, CNNs, and Vision Transformers (ViT, CLIP).
- Advanced Retrieval: Sparse/dense retrieval funnels, advanced chunking (semantic, late), and graph-based approaches (RAPTOR, GraphRAG).
- Enterprise Architecture & Guardrails: Prompt optimization, guardrail pipelines, query transformations, derivative artifacts, and semantic caching.
- Agentic Systems & Fine-Tuning: Text-to-SQL, RLHF, GRPO, and PEFT/ LoRA.
- Evaluation: Retrieval and generation metrics (NDCG, Ragas), plus LLM-as-a-judge.
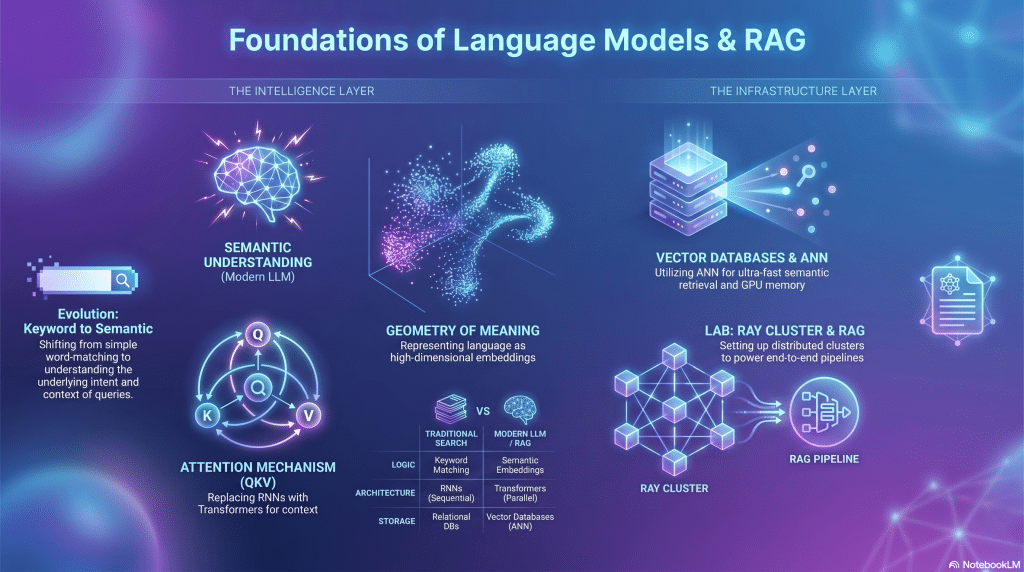
Focus
Understanding the shift from traditional keyword search to semantic machine understanding, exploring the evolution toward Transformers, and the mathematical foundations of attention and high-dimensional vectors.
Key Takeaways
- Evolution of Search: From keyword matching to semantic search and handling language ambiguity.
- Attention Mechanisms: The evolution from RNNs to Transformers, the formal self-attention equation (Query, Key, Value), and the quadratic cost of attention.
- Geometry of Meaning: Translating text to high-dimensional embedding vectors, the curse of dimensionality, and concentration of measure.
- Vector Databases: Approximate Nearest Neighbor (ANN) search and the industrial reality of GPU memory and latency.
Lab
- Environment setup and Lab environment, Access to Ray Cluster
- Simple RAG implementation walkthrough.
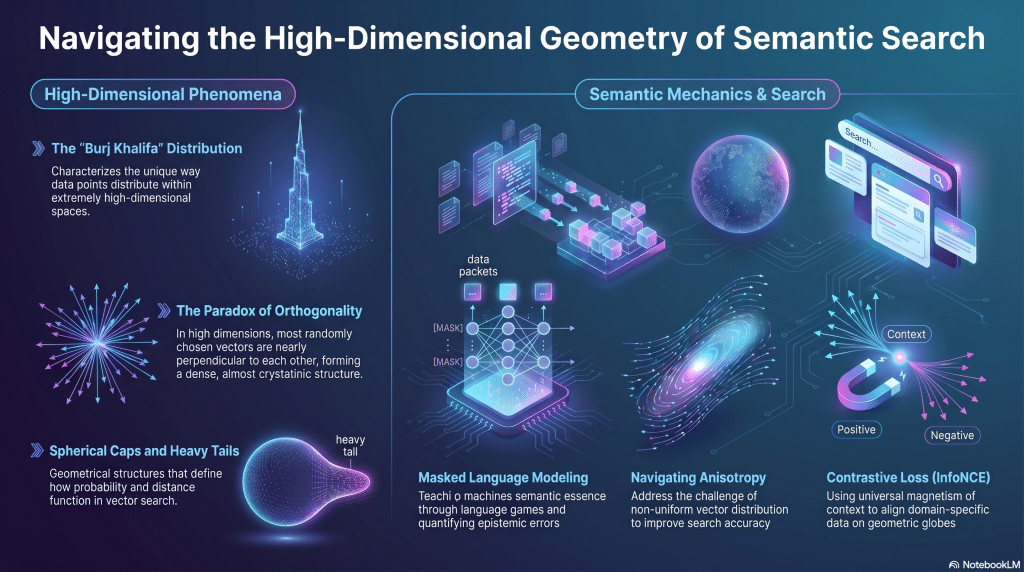
Focus
A deep dive into high-dimensional phenomena, distance ratios, and the mechanics of teaching machines semantic essence through contrastive loss and masked language modeling.
Key Takeaways
- High-Dimensional Phenomena: The “Burj Khalifa” distribution, heavy tails, the paradox of orthogonality, and spherical caps.
- The Journey into BERT: Masked language games, Negative Log Likelihood (NLL), and quantifying epistemic errors.
- Semantic Search Mechanics: The challenge of anisotropy, the role of temperature in probability sand, and navigating from BERT to vector search.
- Contrastive Loss: InfoNCE, domain-specific globes, and the universal magnetism of context and language.
Lab
- Embedding Basics
- Contrastive Loss
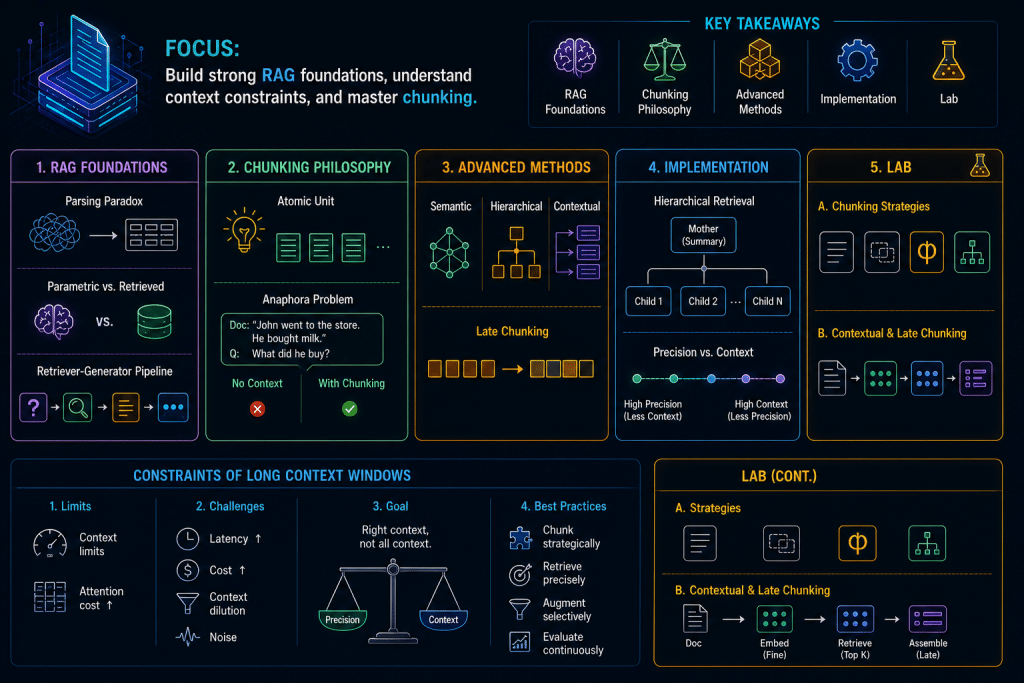
Focus
Establishing the foundations of Enterprise RAG, analyzing the constraints of long context windows, and mastering both fundamental and advanced document chunking methodologies.
Key Takeaways
- Foundations of RAG: The parsing paradox, parametric vs. retrieved memory, and the core retriever-generator pipeline.
- The Philosophy of Chunking: Determining the atomic unit of thought and addressing the anaphora problem.
- Advanced Methodologies: Semantic and hierarchical chunking, the paradigm shift of Late Chunking, and contextual chunking.
- Implementation: Hierarchical retrieval strategies (mother/child chunks) and navigating the precision vs. context continuum.
Lab
- Chunking strategies
- Contextual chunking, Late chunking
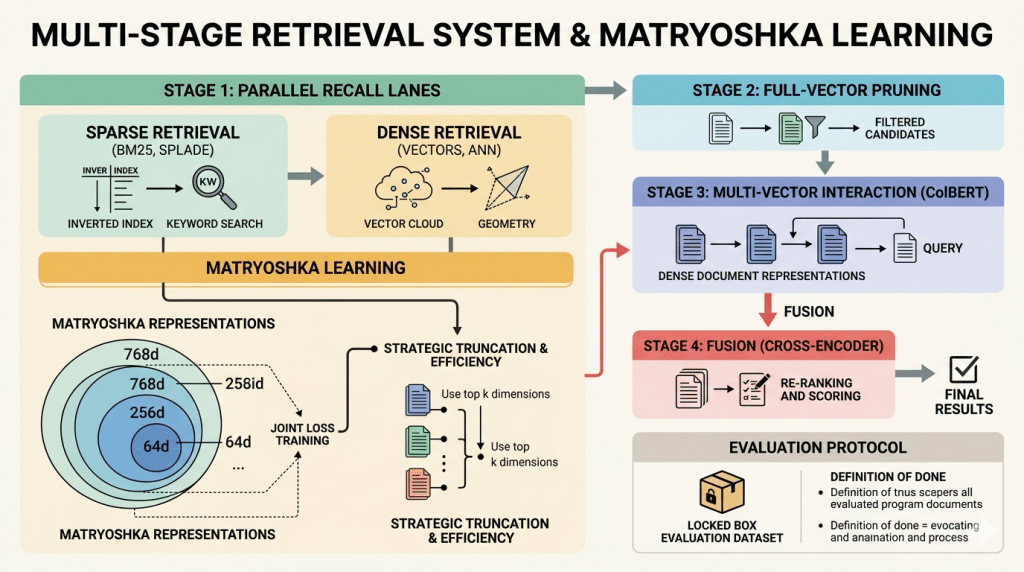
Focus
Structuring a robust multi-stage retrieval system, transitioning from sparse keyword indices to dense vector geometry, and leveraging Matryoshka Representation Learning.
Key Takeaways
- Sparse vs. Dense Retrieval: BM25 mechanics, SPLADE, and the geometry of dense vectors.
- Matryoshka Representation Learning: Nested information, joint loss training, strategic truncation, and computational efficiency.
- Reference Architecture: The 4-stage system: Parallel Recall Lanes (Scoop), Full-Vector Pruning, Multi-Vector Interaction (ColBERT), and Fusion (Cross-Encoder).
- Evaluation Protocol: Defining the “Locked Box” evaluation dataset and the definition of done.
Lab
- Matryoshka Representation Learning
- Retrieval pipeline
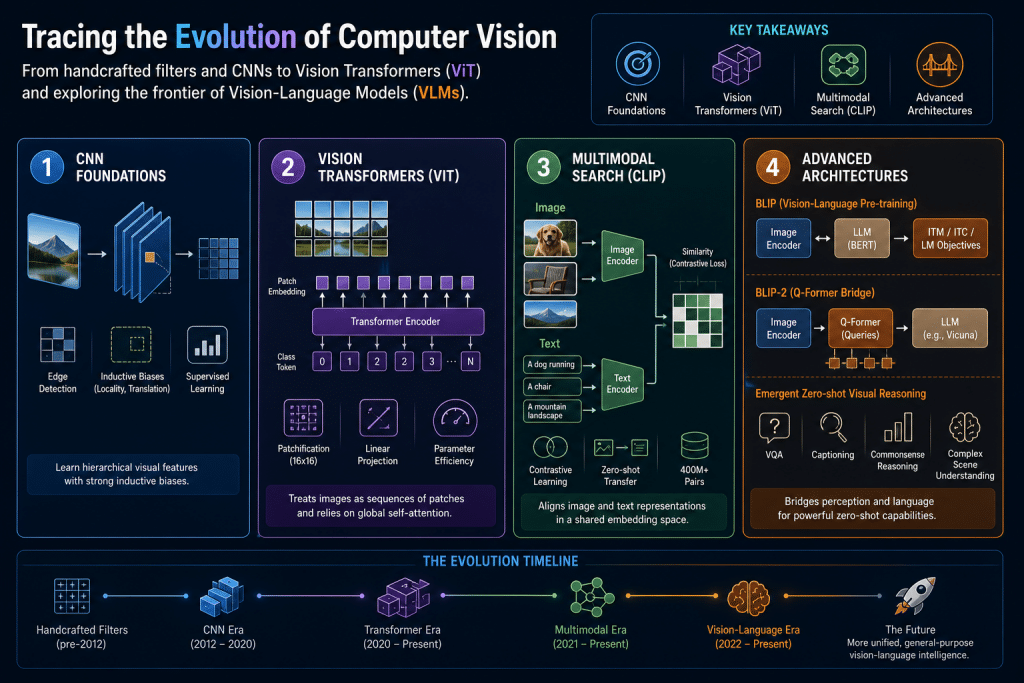
Focus
Tracing the evolution of computer vision from handcrafted filters and CNNs to Vision Transformers (ViT) and exploring the frontier of Vision-Language Models (VLMs).
Key Takeaways
- CNN Foundations: Discrete convolutions, edge detection, inductive biases (locality, translation equivalence), and supervised learning.
- Vision Transformers (ViT): Patchification (“An Image is Worth 16×16 Pixels”), linear projections, and bypassing CNN inductive biases for parameter efficiency.
- Multimodal Search (CLIP): Contrastive loss in multimodal learning, zero-shot transfer, and the 400-million pair data challenge.
- Advanced Architectures: BLIP and BLIP-2 strategy, the Q-Former bridge, and emergent zero-shot visual reasoning.
Lab
- ViT and CNN based classification
- Vision language understanding (CLIP, BLIP, BLIP-2)
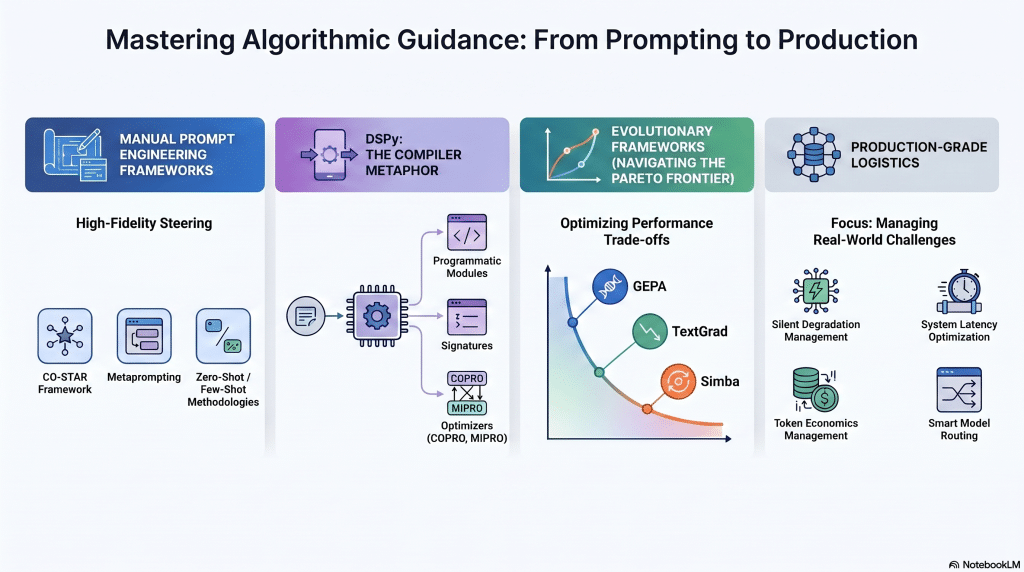
Focus
Mastering the art of steering language models, from crafting high-fidelity human prompts to leveraging programmatic prompt optimization and evolutionary algorithms.
Key Takeaways
- Prompt Engineering: The CO-STAR framework, handling epistemic uncertainty, metaprompting, and zero-shot vs. few-shot methodologies.
- DSPy and Optimization: The compiler metaphor (Signatures, Modules, Optimizers), COPRO, and MIPRO for joint space optimization.
- Evolutionary Frameworks: The GEPA framework (Genetic-Pareto), TextGrad, ORPO, Simba, and navigating the Pareto frontier.
- Production Realities: Managing silent prompt degradation, system latency, token economics, and model routing.
Lab
- Prompt Engineering
- Prompt Optimization
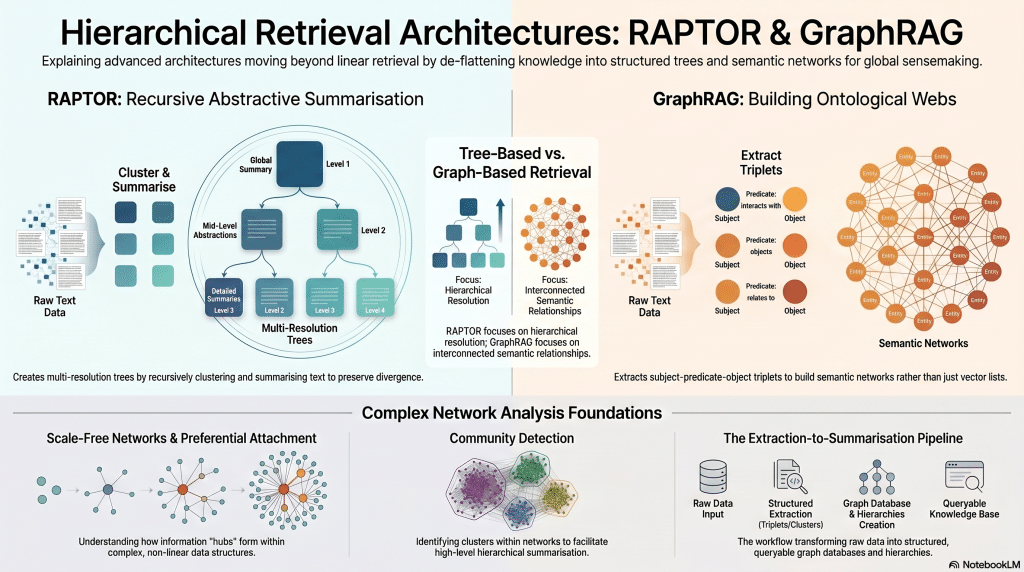
Focus
Moving beyond linear retrieval by de-flattening knowledge into hierarchical trees (RAPTOR) and interconnected semantic networks (GraphRAG) for global sensemaking.
Key Takeaways
- RAPTOR Architecture: Recursive abstractive summarization, multi-resolution representation, and preserving divergence in hierarchical trees.
- GraphRAG Framework: Distinguishing GraphRAG from graph-augmented RAG, extracting triplets, and building ontological webs.
- Complex Network Analysis: Preferential attachment, scale-free networks, and community detection for hierarchical summarization.
- Infrastructure: Graph databases, query languages, the extraction-to-summarization pipeline, and GraphRAG vs. LightRAG.
Lab
- RAPTOR using library
- GraphRAG/LightRAG
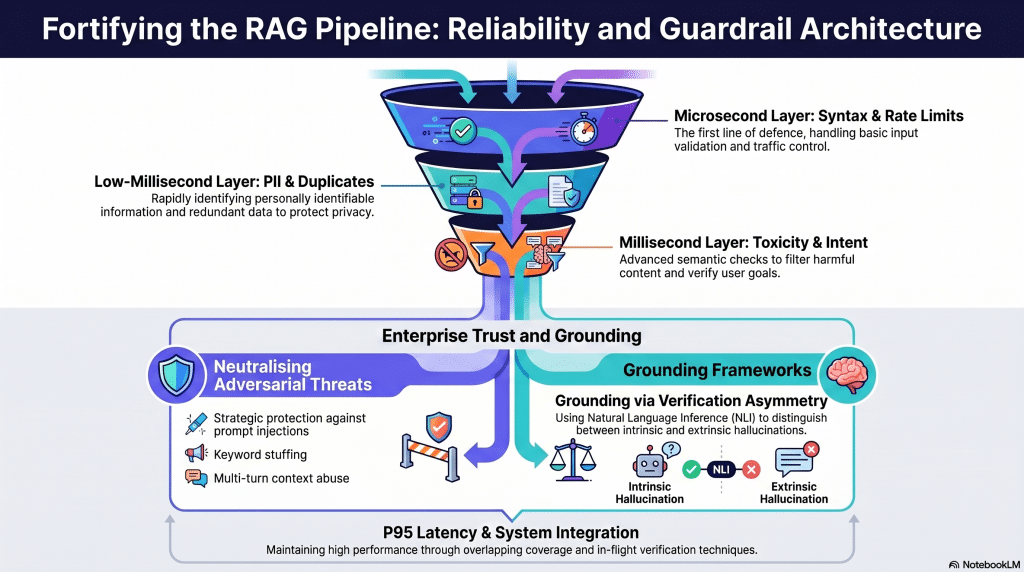
Focus
Identifying failure modes in RAG systems and engineering defensive pipelines and grounding frameworks to ensure enterprise reliability, security, and trust.
Key Takeaways
- The Guardrail Pipeline: The funnel principle of defense spanning microsecond (syntax, rate limits), low-millisecond (PII, duplicates), and millisecond (toxicity, intent) layers.
- Adversarial Threats: Prompt injections, keyword stuffing, and multi-turn context abuse.
- Grounding Frameworks: Intrinsic vs. extrinsic hallucinations, the principle of verification asymmetry, and Natural Language Inference (NLI).
- System Integration: P95 latency standards, overlapping coverage, and in-flight verification techniques.
Lab
- Guardrails
- Response Grounding
Focus
Elevating baseline RAG to enterprise standards by utilizing derivative artifacts, sophisticated query transformation pipelines, and semantic caching optimization.
Key Takeaways
- Derivative Artifacts: Factoids (atoms of meaning), question-answer (QA) pair extraction, and rewriting for findability.
- Query Transformation Pipeline: Spelling correction, context injection, jargon expansion, multi-hop decomposition, and HyDE.
- Semantic Caching: Threshold optimization (), memory management, cache partitioning, and the “re-embedding tax.”
- Embedding Optimization: Hard negative mining, domain-specific fine-tuning, and evaluating via Precision-Recall curves.
Lab
- Derivative artifacts
- Query Transformation Pipeline
- Semantic Cache (Lab mapping: Semantic Cache is covered across Weeks 9/10 practicals)

Focus
Transitioning to dynamic workflows using multi-agent systems and integrating structured databases into unstructured queries via advanced Text-to-SQL generation.
Key Takeaways
- Understanding Agents: The agentic lifecycle, the Model Context Protocol (MCP), and agent specialization patterns.
- Text-to-SQL Architecture: Bridging natural language and relational algebra, resolving schema epistemic uncertainty, and handling shadow DDLs.
- Network Theory in SQL: Schema partitioning, community detection, and finding lynchpin tables.
- Advanced SQL Mining: CTE libraries, reverse generation of use cases, and Reinforcement Learning in SQL generation.
Lab
- Semantic Cache
- ADK, MCP, A2A Condensed Version
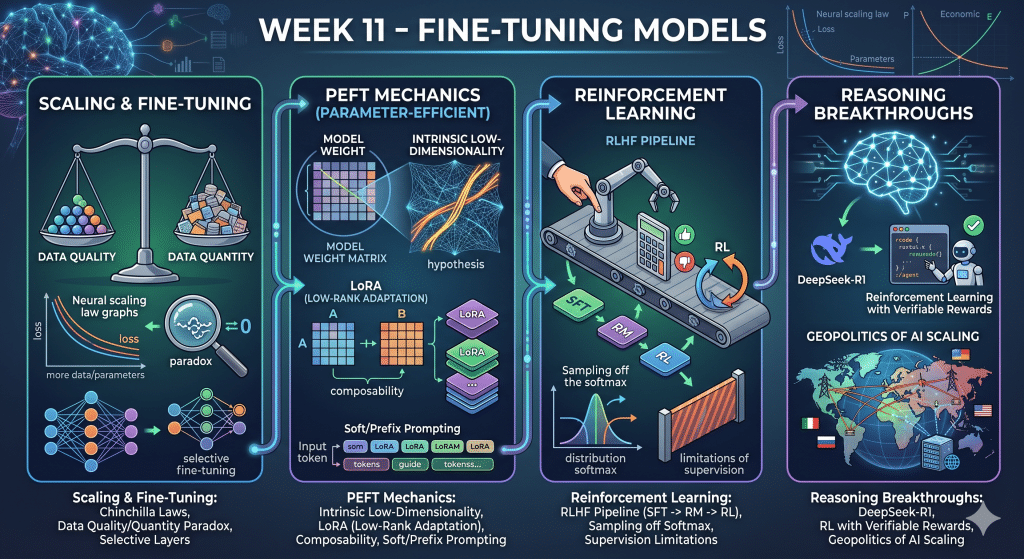
Focus
Exploring the economics and mechanics of adapting models through Supervised Fine-Tuning (SFT), Parameter-Efficient Fine-Tuning (PEFT), and Reinforcement Learning (RL).
Key Takeaways
- Scaling and Fine-Tuning: Neural scaling laws (Chinchilla), the paradox of data quality vs. quantity, and selective layer fine-tuning.
- PEFT Mechanics: The hypothesis of intrinsic low-dimensionality, LoRA (Low-Rank Adaptation), composability, and soft/prefix prompting.
- Reinforcement Learning: The RLHF pipeline (SFT -> RM -> RL), sampling off the softmax, and the limitations of supervision.
- Reasoning Breakthroughs: DeepSeek-R1, Reinforcement Learning with Verifiable Rewards, and the geopolitics of AI scaling.
Lab
- Text2Sql
- Fine-tuning methods, Basic TRL GRPO
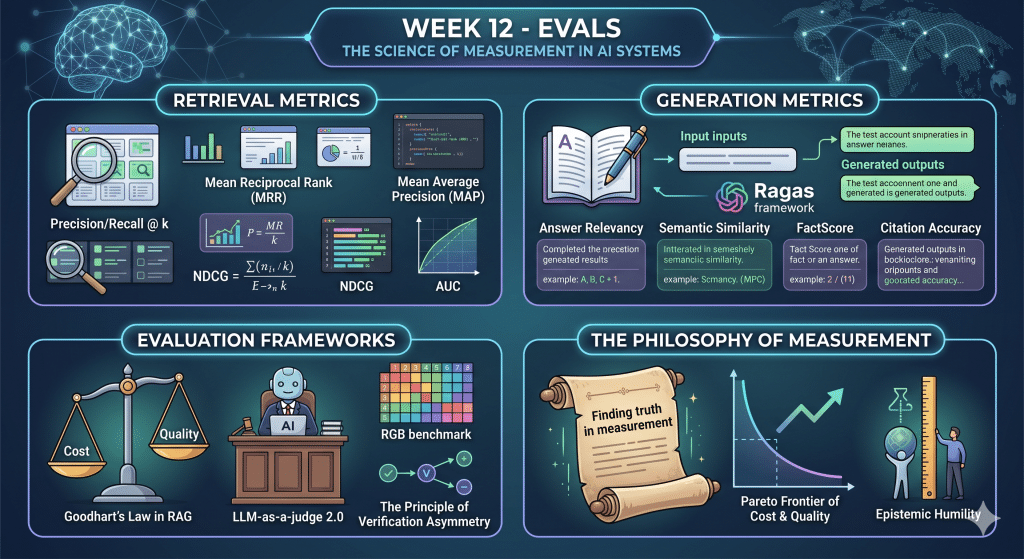
Focus
The science of measurement in AI systems, establishing rigorous, domain-specific benchmarking for both the retrieval and generation components of RAG pipelines.
Key Takeaways
- Retrieval Metrics: Precision/Recall @ k, Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), NDCG, and AUC.
- Generation Metrics: The Ragas framework, answer relevancy, semantic similarity, FactScore, and citation accuracy.
- Evaluation Frameworks: Goodhart’s Law in RAG, LLM-as-a-judge 2.0, the RGB benchmark, and the principle of verification asymmetry.
- The Philosophy of Measurement: Finding , navigating the Pareto frontier of cost and quality, and the ultimate measure of epistemic humility.
Lab
- Unsloth walkthrough
- RAG Evals
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.

Krishnan Ramaswamy
Co-Instructor
Background
Krishnan Ramaswamy is an engineering leader, AI practitioner, and educator with an M.S. in Computer Science and Engineering and more than 25 years of industry experience. Throughout his career, he has designed and delivered large-scale platforms, enterprise applications, and AI/ML-driven solutions across Collaboration, Security, and Customer Experience domains. His expertise includes AI engineering, large language models, retrieval systems, agent architectures, distributed systems, and enterprise platform development. He is passionate about transforming emerging research into production-ready solutions that deliver measurable business value.
Educator
As a co-instructor at SupportVectors, Krishnan mentors engineers and technology professionals on modern AI engineering practices, helping them understand not only how AI systems are built, but also how they can be deployed, evaluated, governed, and scaled in enterprise environments. His teaching combines deep technical knowledge with real-world experience gained from decades of building and leading engineering initiatives.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.


