Course Overview
Starting on Sunday Morning, February 2nd, 2025
Advanced LLM Bootcamp is an intensive 4-month program designed to equip AI professionals with cutting-edge skills in Prompt Engineering and Retrieval-Augmented Generation (RAG). This dual-phase course combines theory with hands-on practice, empowering engineers to excel in building and optimizing advanced large language model (LLM) applications for real-world challenges. It comprises in-depth lecture/theory sessions, guided labs for building AI models, quizzes, projects on real-world datasets, guided readings of influential research papers, and discussion groups.
The teaching faculty for this workshop comprises the instructor, a supportive staff of teaching assistants, and a workshop coordinator. Together they facilitate learning through close guidance and 1-1 sessions when needed.
You can attend the workshop in person or remotely. State-of-the-art facilities and instructional equipment ensure that the learning experience is invariant of either choice. Of course, you can also mix the two modes: attend the workshop in person when you can, and attend it remotely when you cannot. All sessions are live-streamed, as well as recorded and available on the workshop portal.
Learning Outcome
By the end of the Advanced LLM Bootcamp, participants will master Prompt Engineering and RAG techniques to build and optimize advanced LLM applications. They will gain hands-on experience through labs and projects, developing the skills and confidence to solve real-world AI challenges and showcase a strong portfolio.
Schedule
| Start Date | SUNDAY, FEBRUARY 2nd, 2025 |
|---|---|
| Duration | 4 months |
| Session days | Every Sundays |
| Session timing | 11 AM PST to Evening |
| Session type | In-person/Remote |
| Morning sessions | Theory/Paper Readings |
| Evening sessions | Lab/Presentation |
| LAB Walkthrough | Wednesday, 7 PM to 10 PM |
Call us at 1.855.LEARN.AI for more information.
Skills You Will Learn
Advanced NLP and LLM Expertise, Skills in fine-tuning and optimizing transformer-based models , Specialized in Prompting Methods.
Prerequisites
The teaching faculty for this course comprises the instructor, a supportive staff of teaching assistants, and a course coordinator. Together, they facilitate learning through close guidance and 1-1 sessions when needed.
Target Audience
Prompt Engineering Syllabus
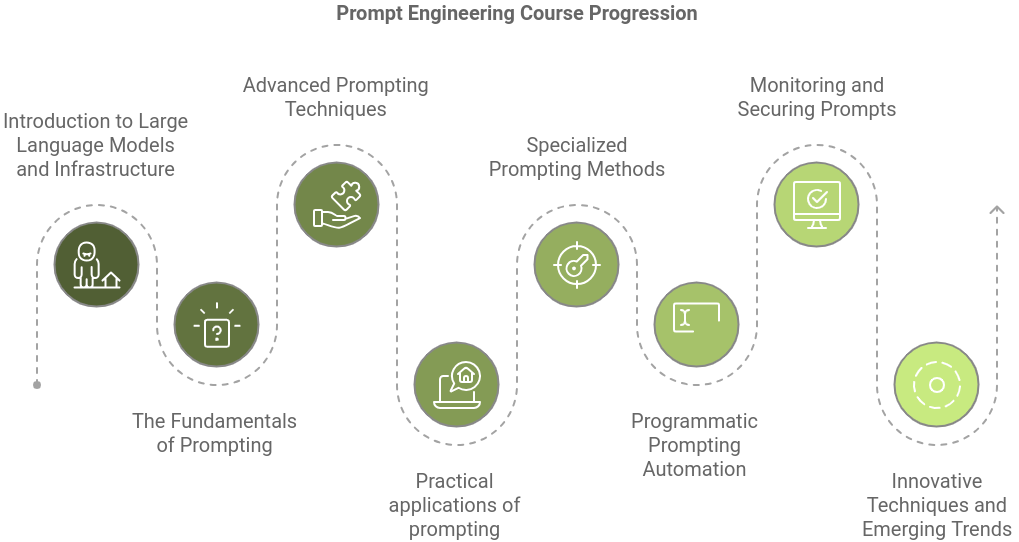
This syllabus provides a structured pathway to mastering the nuances of prompt engineering. From foundational concepts and types of prompting to advanced programmatic automation and observability techniques, this course covers a wide spectrum of topics that cater to both beginners and experienced AI practitioners. Each section is tailored to deepen your knowledge, offering practical insights, real-world case studies, and hands-on demonstrations.
This section ensures that everyone, regardless of their technical background or level of experience, feels comfortable engaging with LLMs. By demystifying the underlying infrastructure and deployment methods, participants will gain the confidence to use and interact with LLMs effectively. This foundation is crucial for setting the stage for more advanced topics in prompt engineering, enabling learners to appreciate the full potential of LLMs while understanding their practical deployment in diverse contexts
LLM Inference Endpoints and Frameworks:
Understand the infrastructure supporting large language models (LLMs) and the frameworks used for deploying them in real-world applications. This will cover cloud-based solutions, API endpoints, and efficient ways to integrate LLMs into various services.
You will be equipped with the foundational knowledge necessary for understanding the art of prompt design, laying the groundwork for advanced techniques that allow you to better guide the AI to produce the desired output.
Overview of Prompting:
A deep dive into the basics of prompting, including the different types of prompts (text, visual, audio, video) and how they can be used to interact with AI models. Learn the strategies for crafting effective prompts.
Prompting as Control Flow:
Explore how to use prompts to guide the sequence of AI operations. You will learn techniques for controlling the behavior and flow of a model’s output based on different types of input.
Dive into advanced techniques for prompting, addressing both the strengths and weaknesses of LLMs. By the end of this segment, you’ll have the tools to push the boundaries of what these models can achieve.
Limitations of LLMs and Manual Prompting:
Understand the inherent limitations of LLMs and how manual prompting can be optimized to mitigate these limitations. This includes handling common challenges such as bias, lack of context, and model unpredictability.
COSTAR and Other Prompting Techniques:
Learn about COSTAR and other state-of-the-art prompting techniques. Discover how these methods allow you to extract more nuanced responses from LLMs for complex tasks.
These practical examples will showcase how prompt engineering can be applied across different domains, helping you connect theory with real-world usage. You’ll understand how to make the most of prompting in diverse contexts
Case Studies & Domain Applications:
Explore real-world applications of prompt engineering across various industries such as healthcare, finance, and entertainment. Through case studies, see how companies are leveraging advanced prompting techniques to solve complex problems
Prompting in Structured Output Generation:
Learn how to design prompts that generate structured outputs, such as tables, JSON data, or code, to ensure your AI systems respond in useful and predictable formats.
Specialized techniques such as function-based prompting and constrained sampling enable you to harness advanced functionality and precision in your AI responses. This section will introduce you to cutting-edge tools for more targeted prompt engineering.
Function Call-based Prompting (Instructor-Led):
Understand how to use function calls to structure prompts dynamically. Learn how this technique allows you to use external functions to guide the model’s behavior during prompt execution.
Constrained Sampling:
Explore methods for constrained sampling that help refine your prompts, ensuring the AI produces only the most relevant responses.
Constrained Sampling: Microsoft Guidance:
Learn about Microsoft’s approach to constrained sampling, a method for optimizing and controlling the outputs of LLMs in specific applications.
This section focuses on automation techniques that will allow you to scale your prompting process and integrate new tools for streamlined, programmatic prompt creation.
Programmatic Prompting and Automation:
Learn how to automate the prompt generation process using programming techniques, saving time and improving efficiency in deploying prompts at scale.
Programmatic Prompting: DSPy:
Explore DSPy, a tool designed to help automate and optimize the prompting process. Learn how to integrate it into your workflow to streamline prompt development.
Programmatic Prompting: SAMMO:
Discover SAMMO, an advanced framework that allows for deep automation in the prompt generation process, enhancing your ability to work with large-scale systems.
Learn how to monitor, evaluate, and secure your prompts in production environments. This is a critical part of working with AI systems at scale, ensuring your work is both effective and safe.
Prompt Monitoring:
Understand techniques for monitoring the effectiveness of your prompts in real-time. Learn how to observe AI performance and adjust prompts accordingly to optimize results.
LLM Observability:
Delve into tools like Arize Phoenix, LogFire, and LangFuse to monitor the performance of LLMs. These tools help ensure that your models are running efficiently, securely, and reliably.
Prompt Security:
Explore methods for securing prompt engineering processes, ensuring that data integrity, privacy, and model safety are maintained while interacting with AI systems.
Synthetic Data Generation:
Discover how to generate synthetic data for testing and optimizing prompts. Learn how this can help in situations where real data is scarce or sensitive.
TextGrad: Advanced Techniques for Secure Prompt Engineering:
Learn about the latest techniques, including TextGrad, for advancing prompt engineering in a secure and scalable way, ensuring that your prompts can handle a wide range of tasks without compromising on accuracy or security.
RAG to Riches Syllabus

This curriculum spans six Sundays and six weeks of projects and labs. Each week has its theme, giving us time to explore it in considerable practical and foundational detail. The outcome of each week should be a reasonably expert-level proficiency in the topics at hand.
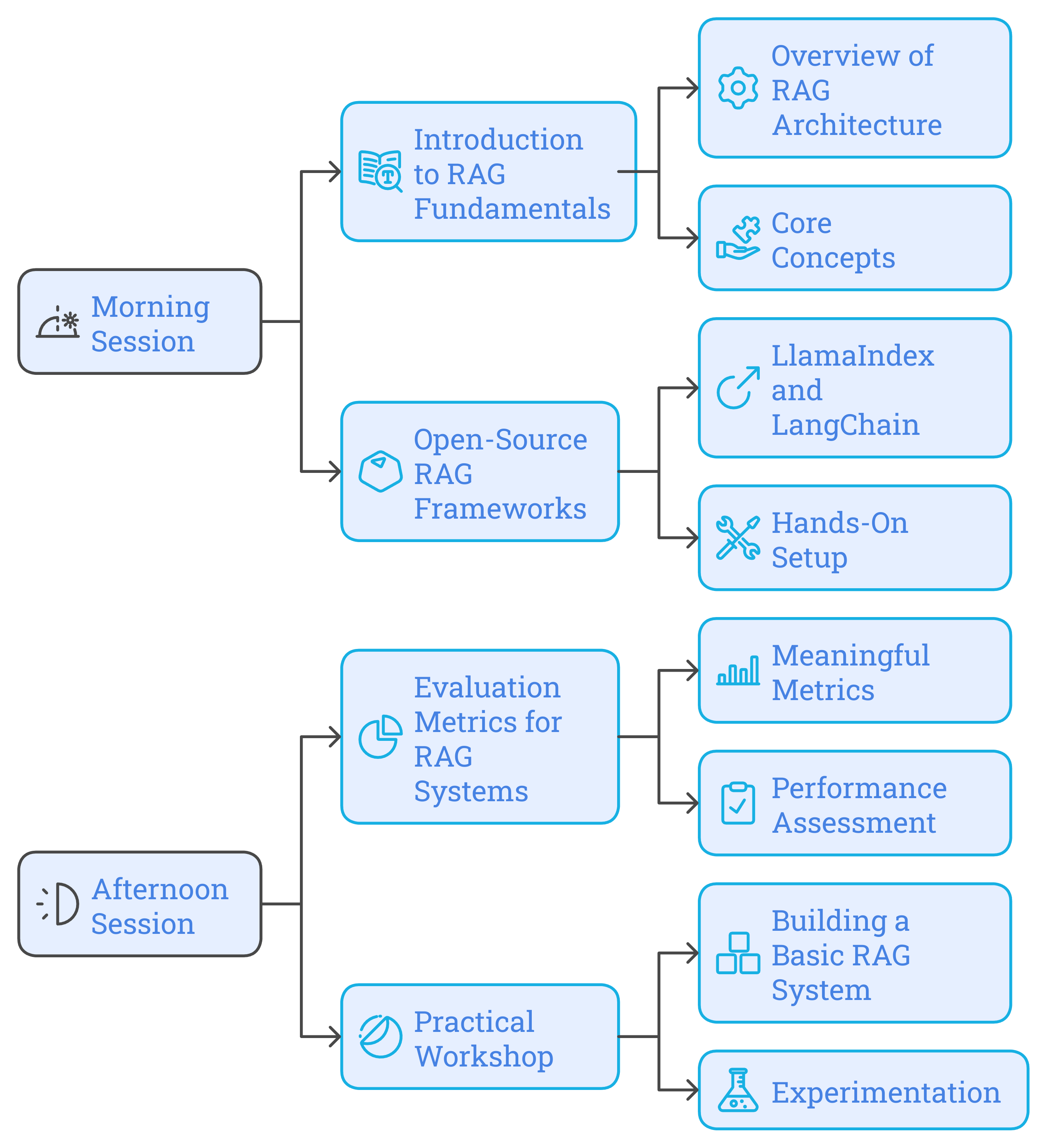
Morning Session:
- Introduction to RAG Fundamentals
- Overview of RAG Architecture: Understanding how retrieval mechanisms enhance language generation.
- Core Concepts: Differentiating between retrieval and generation components.
- Open-Source RAG Frameworks
- LlamaIndex and LangChain: Exploring features, capabilities, and use-cases.
- Hands-On Setup: Installing and configuring these frameworks for development purposes.
Afternoon Session:
- Evaluation Metrics for RAG Systems
- Meaningful Metrics: Precision, recall, F1-score, and their relevance in RAG.
- Performance Assessment: Techniques for evaluating both retrieval and generation quality.
- Practical Workshop
- Building a Basic RAG System: Using open-source frameworks to create a simple application.
- Experimentation: Tweaking parameters and observing effects on output quality.
Practical Value: Establishing a solid foundation equips engineers with the essential tools and understanding needed to develop sophisticated RAG systems. Familiarity with open-source frameworks accelerates the development process and encourages best practices.

Morning Session:
- Vector Databases and ANN-Indexing Approaches
- Understanding Approximate Nearest Neighbors (ANN): Techniques like HNSW, FAISS, and their algorithms.
- Performance vs. Efficiency Trade-offs: Balancing speed and accuracy in large-scale applications.
- Text Encoders
- Survey of Text Encoders: From traditional TF-IDF to transformer-based models like BERT.
- Architectures and Trade-offs: Comparing computational costs and performance metrics.
Afternoon Session:
- Re-Ranking with Cross-Encoders
- Hybrid Search Strategies: Combining keyword-based and vector embedding searches.
- Implementation Techniques: Enhancing retrieval results with cross-encoder models.
- Hands-On Lab
- Implementing Vector Databases: Setting up and querying with different ANN indexes.
- Encoder Comparison: Testing various text encoders and analyzing their impact on retrieval quality.
Practical Value: Mastery of retrieval components is crucial for building efficient RAG systems. Understanding the underlying mechanisms allows engineers to optimize performance and scalability according to specific project needs.
 Morning Session:
Morning Session:
- Effective Semantic Chunking Methods
- Techniques like Raptor and Content-Rewrite: Improving retrieval granularity and relevance.
- Chunking Strategies: Deciding on chunk sizes and overlap for optimal performance.
- COLBERT and Late-Interaction Methods
- Concepts of Late Interaction: How COLBERT enhances retrieval accuracy.
- Implementation Details: Setting up COLBERT models and integrating them into RAG systems.
Afternoon Session:
- RAG over Graphs, Figures, and Tables
- Non-Textual Data Retrieval: Techniques for handling structured and semi-structured data.
- Integration Strategies: Merging textual and non-textual data retrieval in RAG.
- Project Work
- Implementing Advanced Techniques: Applying semantic chunking and late-interaction methods to a RAG system.
- Evaluation and Optimization: Measuring improvements and refining the system.
Practical Value: Advanced retrieval techniques significantly enhance the capability of RAG systems to handle complex queries and diverse data types, which is essential for developing robust AI applications.
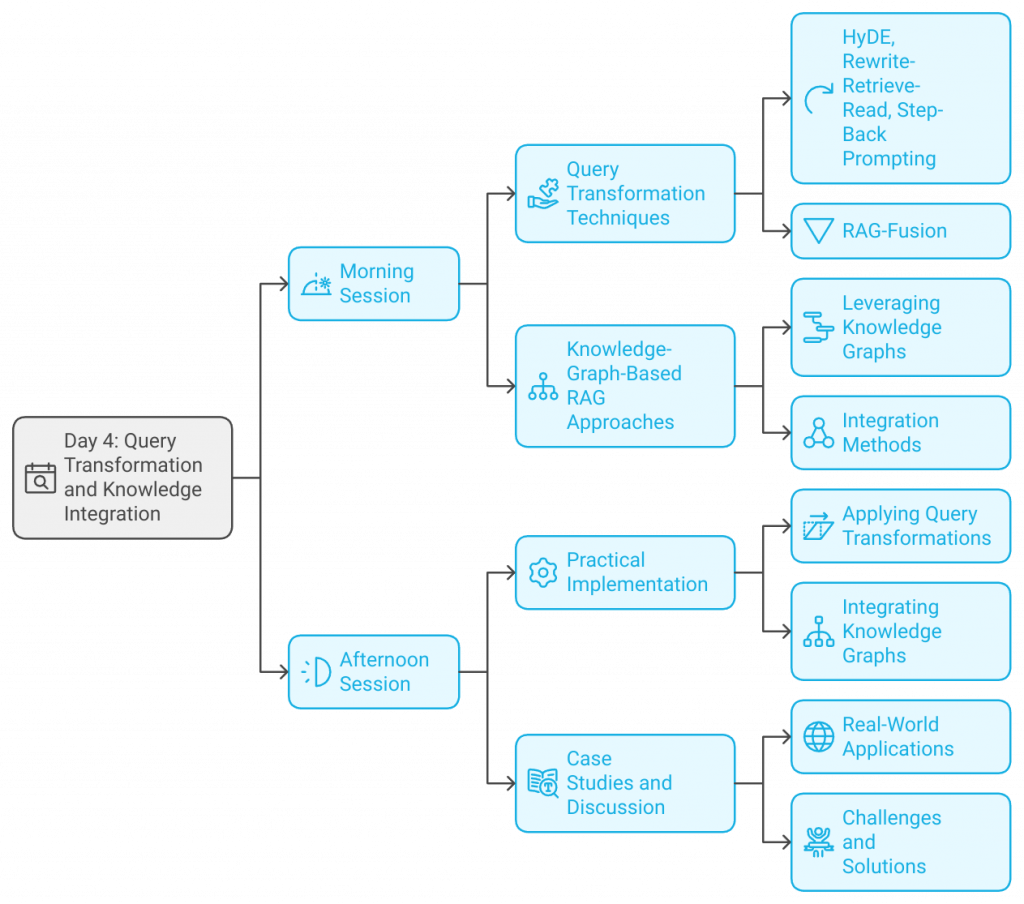
Morning Session:
- Query Transformation Techniques
- HyDE, Rewrite-Retrieve-Read, Step-Back Prompting: Methods to reformulate queries for better retrieval.
- RAG-Fusion: Combining multiple retrieval results for enriched generation.
- Knowledge-Graph-Based RAG Approaches
- Leveraging Knowledge Graphs: Enhancing context and relevance in responses.
- Integration Methods: Connecting knowledge graphs with retrieval and generation components.
Afternoon Session:
- Practical Implementation
- Applying Query Transformations: Developing modules that reformulate queries.
- Integrating Knowledge Graphs: Building a RAG system that utilizes knowledge graphs for improved results.
- Case Studies and Discussion
- Real-World Applications: Examining how companies use these techniques in production.
- Challenges and Solutions: Addressing common obstacles in implementation.
Practical Value: Query transformation and knowledge integration are pivotal for creating intelligent RAG systems that can understand and respond to user queries more effectively, thereby improving user satisfaction and system utility.
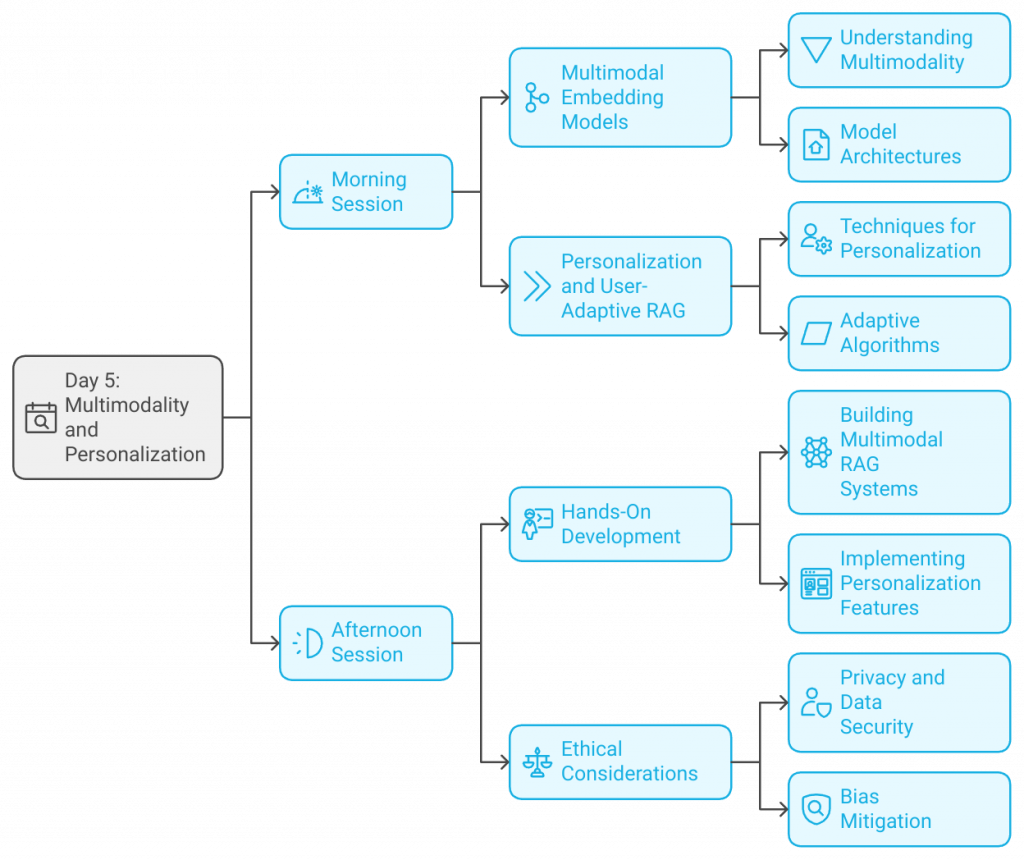
Morning Session:
- Multimodal Embedding Models
- Understanding Multimodality: Combining text, images, audio, and other data types.
- Model Architectures: Exploring models like CLIP that handle multimodal data.
- Personalization and User-Adaptive RAG
- Techniques for Personalization: User profiling, context awareness, and preference learning.
- Adaptive Algorithms: Methods for tailoring responses based on individual user data.
Afternoon Session:
- Hands-On Development
- Building Multimodal RAG Systems: Incorporating different data types into retrieval and generation.
- Implementing Personalization Features: Developing algorithms that adapt to user behaviors.
- Ethical Considerations
- Privacy and Data Security: Ensuring user data is handled responsibly.
- Bias Mitigation: Strategies to prevent biased outputs in personalized systems.
Practical Value: Incorporating multimodality and personalization makes RAG systems more versatile and user-friendly, which is essential in developing AI solutions that meet users’ diverse needs in real-world scenarios.
Morning Session:
- Fine-Tuning Models
- Embedding Models and LLMs: Techniques for adapting pre-trained models to specific tasks.
- Training Strategies: Transfer learning, domain adaptation, and hyperparameter tuning.
- Efficient Data Ingestion Pipelines for RAG
- Handling Large-Scale Data: Methods for ingesting and processing vast amounts of information.
- Preprocessing and Normalization: Ensuring data quality and consistency.
- Augmentation Strategies: Enhancing datasets to improve model performance.
Afternoon Session:
- Capstone Project
- Building a Comprehensive RAG System: Integrating all learned components into a final project.
- Optimization and Deployment: Preparing the system for real-world application.
- Review and Next Steps
- Course Recap: Summarizing key takeaways from each module.
- Further Learning Resources: Guiding continued education and exploration.
Practical Value: Fine-tuning models and efficient data handling are critical for deploying high-performance RAG systems in production environments. These skills ensure that engineers can deliver scalable and effective AI solutions.
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Kayalvizhi T
Indira Gandhi National Univ

Ravi Sati
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.


