Course Overview
Starting TBD
This course is designed to introduce you to the foundational and advanced concepts of artificial intelligence, with a focus on neural networks, large language models, and generative AI.
Through a combination of lectures, hands-on coding exercises and project work, you will gain a deep understanding of the mathematical and technical underpinnings of AI technologies.
Learning Outcome
You will develop both a theoretical fluency and hands-on PyTorch coding expertise in neural network architectures, llm and generative AI.
Skills you will learn
PyTorch, Autoencoder, GAN, CNN, RNN, Neural Network Architectures
Prerequisites
| START DATE | TBD |
|---|---|
| Duration | 12 weeks |
| Theory Session | Every Wednesday, 7 PM to 9:30 PM PST |
| Lab Session |
Monday, 7 PM to 9:30 PM PST (Summary and Quiz) Tuesday, 7 PM to 9:30 PM PST (Lab) |
Call us at 1.855.LEARN.AI for more information.

Syllabus details

In this course, you will gain a strong foundation in the mathematical principles behind AI, including the Universal Approximation Theorem that demonstrates the power of neural networks in approximating complex functions.
You’ll explore essential neural network concepts such as activation functions, backpropagation, regularization, and optimization techniques, all of which are critical for building and training effective models.
The course covers key neural network architectures, including feed-forward networks, CNNs (for image processing), RNNs (for sequential data), and Transformers (used in NLP and beyond).
You’ll also delve into advanced generative models like Autoencoders, GANs, Diffusion Models, Normalized Flows, and Energy-Based Models, gaining hands-on experience in building and applying these models.
Each lecture session will be followed by a Lab session. Through these practical coding exercises and projects, you’ll apply your knowledge to solve real-world AI problems and enhance your understanding of transformer-based architectures, which are at the forefront of AI innovation.

This series offers an introduction to Artificial Intelligence (AI), explaining how we measure and quantify learning in a machine. We will examine the limits of our current understanding of AI systems.
Through historical context, you’ll see how AI development parallels the early stages of industrial innovations, with much of AI’s potential still unfolding. The course lays the foundation for deeper exploration into the exciting and rapidly evolving field of AI.
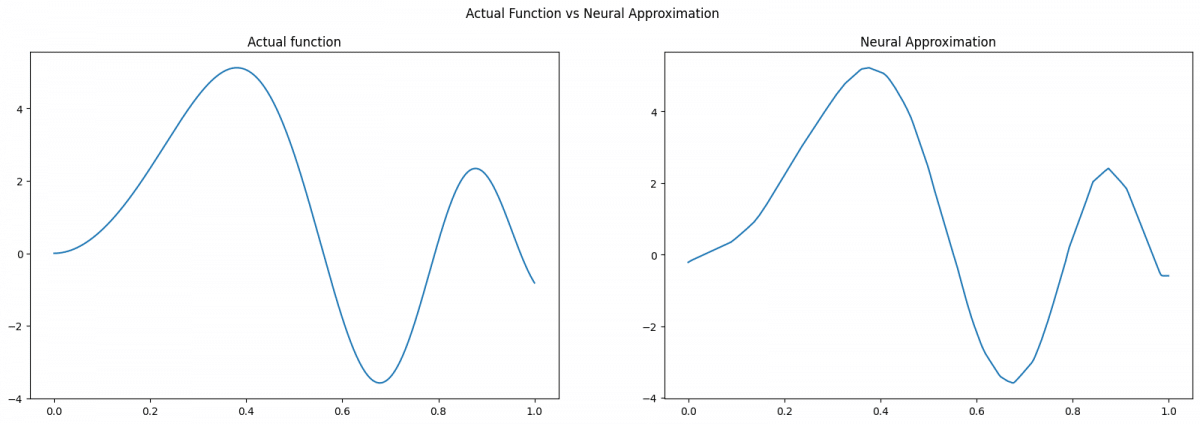
This series explores the Universal Approximation Theorem, which explains why neural networks are powerful function approximators.
A feed-forward network with just one hidden layer can approximate any continuous function with high accuracy, given the right conditions. Understanding this foundational concept reveals why neural networks excel in tasks like image recognition and natural language processing.
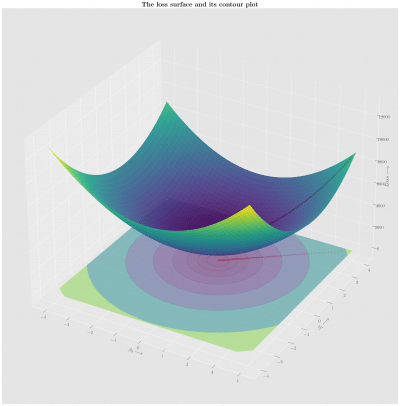
This series covers Gradient Descent, a key optimization algorithm in machine learning that minimizes the cost function by iteratively adjusting model parameters. We will learn how it helps fine-tune models by moving in the direction that reduces errors.
Additionally, we will explore activation functions, which introduce non-linearity into neural networks, enabling them to act as universal function approximators.
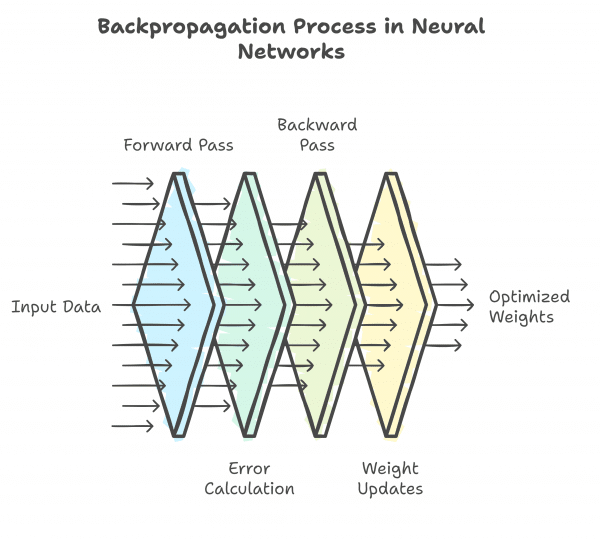
This series introduces Backpropagation, a critical algorithm for training neural networks. It allows networks to learn by adjusting weights to minimize the difference between predicted and actual outputs. By using a loss function to quantify errors, backpropagation calculates gradients and updates weights iteratively, improving the network’s accuracy.
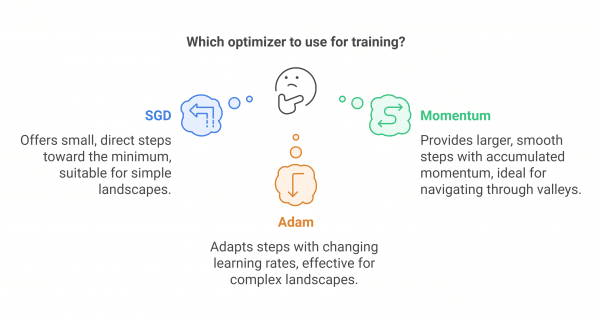
This series explores the role of optimizers and loss functions in training neural networks.
We will explore how optimization algorithms like Stochastic Gradient Descent (SGD), Adam, and AdamW update model parameters to improve performance.
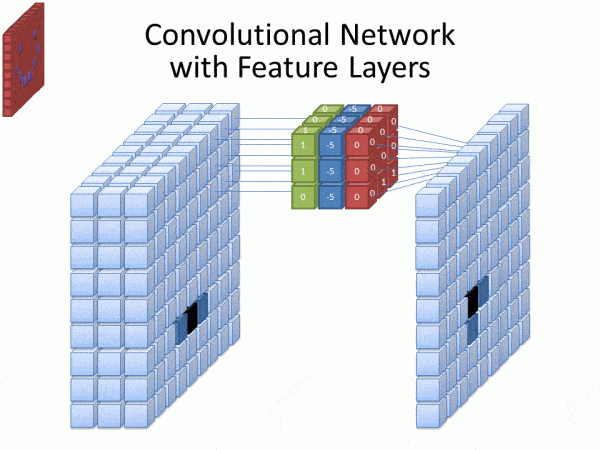
This series covers Convolutional Neural Networks (CNNs), a class of deep neural networks designed for processing grid-like data, such as images.
CNNs are powerful for image recognition, object detection, and semantic segmentation, as they automatically learn spatial hierarchies of features through convolutional layers.
Beyond image tasks, CNNs are also used in video analysis, NLP, and medical image analysis, making them a cornerstone of modern AI applications.
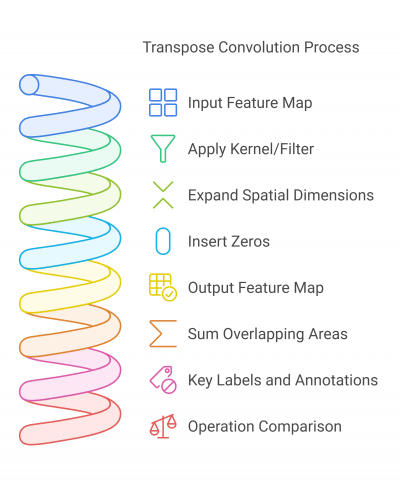
This series introduces Deconvolution (also known as transposed convolution), a key operation in tasks like image generation, semantic segmentation, and feature visualization.
Deconvolution is the inverse of convolution, used to upsample feature maps and reconstruct spatial details.

This series covers Autoencoders, powerful deep learning models for learning data representations in an unsupervised manner. Autoencoders compress input data into a lower-dimensional latent space and then reconstruct it to its original form.
We will explore various types of autoencoders, including Encoder-Decoder-based, CNN-based and Denoising.
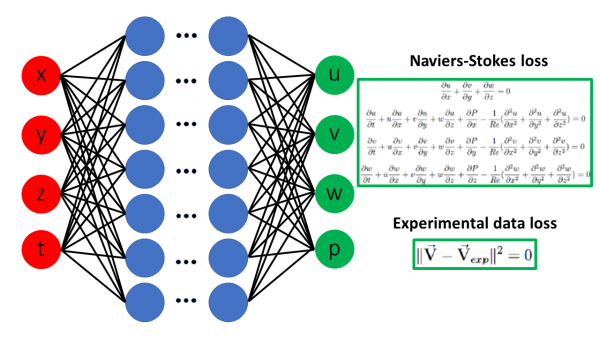
This series introduces Physics-Informed Neural Networks (PINNs), which combine physical laws (often represented by partial differential equations) with data to train more accurate and generalizable models.
Unlike traditional machine learning models, PINNs incorporate both observed data and underlying physics into their loss function.
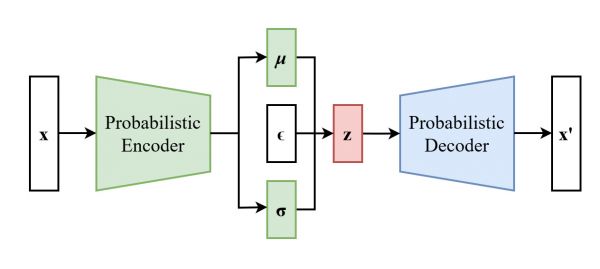
This series covers Variational Autoencoders (VAEs), generative models that learn a probabilistic latent space for data encoding and reconstruction.
VAEs are used for image generation, anomaly detection, and semi-supervised learning.
We will also learn about VQ-VAEs (Vector Quantized Variational Autoencoders), which use a discrete latent space for tasks like speech synthesis and text-to-speech, optimizing embeddings through codebook and commitment losses.

This series covers Generative Adversarial Networks (GANs), a groundbreaking class of models where two neural networks, the generator and discriminator, engage in a competitive game.
We will delve into different types of GANs like conditional GANs, CycleGAN, Wasserstein GAN (WGAN), Spectral Normalization GAN (SNGAN) and others.
This series covers Self-Attention, a mechanism that allows models to focus on relevant parts of input data by computing weighted relationships between elements in a sequence using query, key, and value vectors.
The Transformer architecture leverages self-attention to revolutionize tasks like natural language processing, replacing recurrent and convolutional layers.
In this series, we will explore the various types of Transformer architectures, each tailored to specific tasks in machine learning and artificial intelligence.
We will dive deep into Encoder-only transformers, Decoder-only transformers, Encoder-decoder transformers, Multimodal transformers etc.

This series covers Transformers and Diffusion Models, two powerful generative models.
Transformers excel in tasks like text generation and multimodal learning using self-attention mechanisms.
Diffusion Models, on the other hand, generate high-quality data by learning to reverse a noise-adding process, offering stable training and photorealistic outputs for applications like image generation and text-to-image translation.
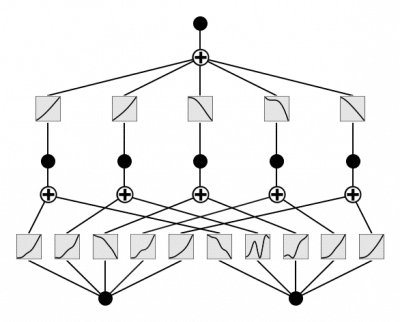
This series introduces Kolmogorov-Arnold Networks (KANs) and the Kolmogorov-Arnold Theorem (KAT), which form the foundation for advanced function approximation in neural networks.
KANs are neural networks inspired by KAT, which states that any continuous multivariate function can be represented as a composition of simpler functions, like sigmoidal functions.
This series explores the rapid evolution of neural networks and their transformative impact across various fields.
From early architectures to advanced models like CNNs, transformers, and generative models, we will explore how key innovations such as self-attention mechanisms and scaling laws have revolutionized AI’s capabilities.
Finally, we’ll discuss the ethical considerations and future directions of AI, focusing on its potential to solve global challenges and reshape industries.
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.

Krishnan Ramaswamy
Co-Instructor
Background
Krishnan Ramaswamy is an engineering leader, AI practitioner, and educator with an M.S. in Computer Science and Engineering and more than 25 years of industry experience. Throughout his career, he has designed and delivered large-scale platforms, enterprise applications, and AI/ML-driven solutions across Collaboration, Security, and Customer Experience domains. His expertise includes AI engineering, large language models, retrieval systems, agent architectures, distributed systems, and enterprise platform development. He is passionate about transforming emerging research into production-ready solutions that deliver measurable business value.
Educator
As a co-instructor at SupportVectors, Krishnan mentors engineers and technology professionals on modern AI engineering practices, helping them understand not only how AI systems are built, but also how they can be deployed, evaluated, governed, and scaled in enterprise environments. His teaching combines deep technical knowledge with real-world experience gained from decades of building and leading engineering initiatives.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.

