Course Overview
Starting on Saturday, June 2026
This is the eagerly awaited hackathon-style, coding-centered BootCamp centered around real-world, exciting projects.
You will work in teams of 4-6 engineers in an environment that closely reproduces the innovation and development that is the quintessence of the Silicon Valley spirit. Each team will get a meeting room with a state-of-the-art multimedia setup and a powerful AI server with RTX4090 for exclusive use during the boot camp. These will also be accessible remotely so that the teams can continue to work on them during the workdays.
You will also have unrestricted access to a massive 4-GPU AI server at the admin-privilege level for the three-month duration of this boot camp on a time-shared basis.
Learning Outcome
You should become confident and fluent in applying LLMs to solve an extensive range of real-world problems.
Practical exposure to vector embeddings, semantic AI search, retrieval-augment generation, multi-modal learning, video comprehension, adversarial attacks, computer vision, audio-processing, natural language processing, tabular data, anomaly and fraud detection, healthcare applications, techniques of prompt engineering
Schedule
| START DATE | SATURDAY, June 2026 |
|---|---|
| Periodicity | Meet every Saturday for twelve weeks |
| Schedule | From 11 AM to 5 PM PST |
| Morning Session | 11 AM to 1 PM PST |
| Lunch Served | 1 PM to 1:30 PM PST |
| Afternoon Session | 1:30 PM to 4 PM PST |
| Project Presentations | 4 PM to 5 PM |
| Lab Walkthrough |
Wednesday, 7 PM to 10 PM (Summary and Quiz) Thursday, 7 PM to 10 PM (Lab) |
Skills You Will Learn
Practical exposure to vector embeddings, semantic AI search, retrieval-augment generation, multi-modal learning, video comprehension, adversarial attacks, computer vision, audio-processing, natural language processing, tabular data, anomaly and fraud detection, healthcare applications, techniques of prompt engineering
Prerequisites
Syllabus details
This curriculum spans sixteen Saturdays and sixteen weeks of projects and labs. Each week has its theme, giving us time to explore it in considerable practical and foundational detail. The outcome of each week should be a reasonably expert-level proficiency in the topics at hand.
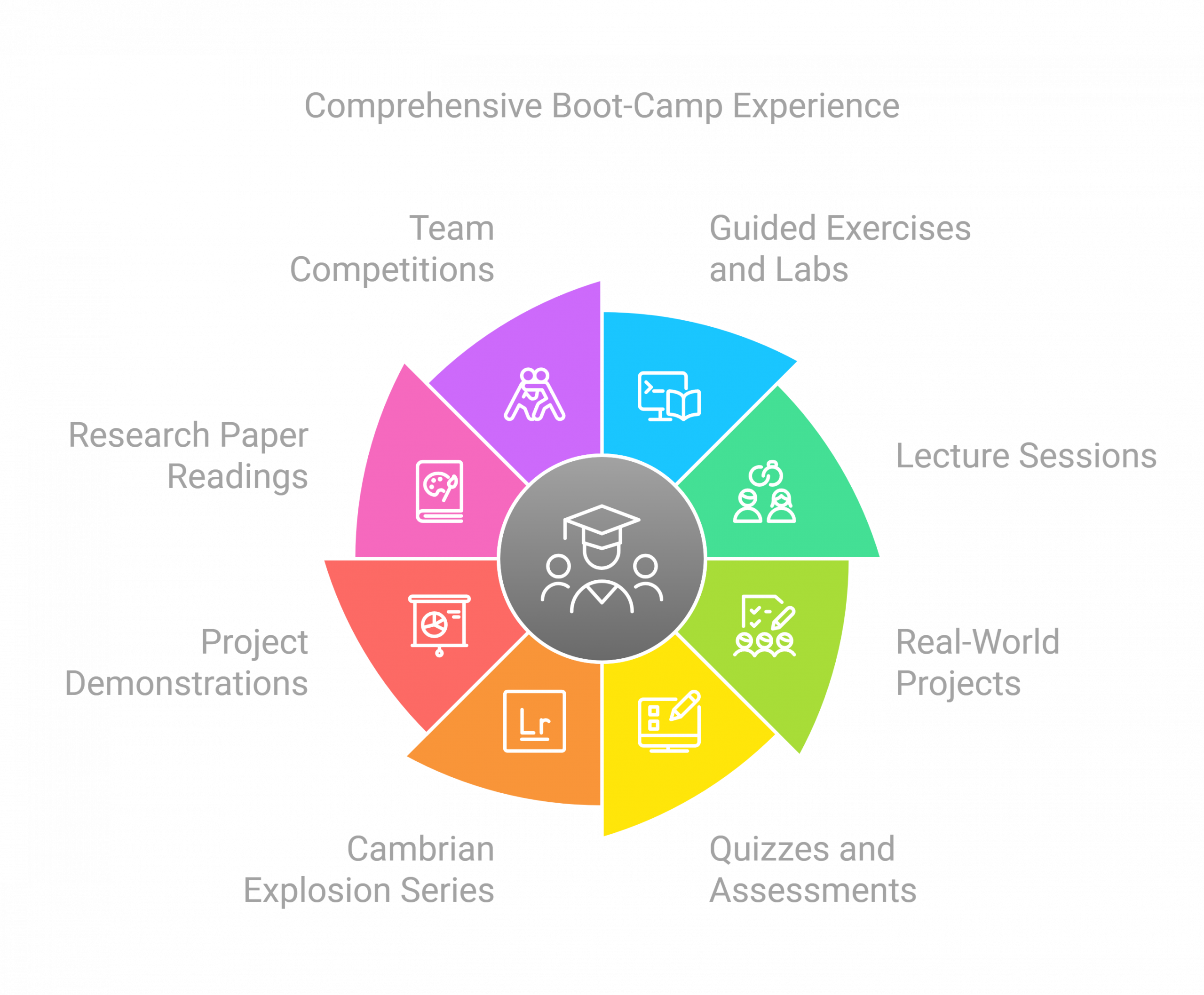
Activities and components of the boot-camp
- An extensive compilation of guided exercises and labs with Jupyter notebooks
- Lecture sessions with clear explanations of the topics involved
- Real-world group projects that aim to be starters for a potential startup, either outside or within your current company/place of work
- Quizzes and assessments for self-evaluation of progress
- “Cambrian Explosion” series — a collective approach to discuss the latest breakthroughs and happenings in LLM
- Project demonstrations and cohort feedback
- Research paper readings with lucid explanations bring out the main ideas and relevance.
- A friendly competition between the teams and sharing of best practices
- A reasonably extensive starter code-base to guide your progress and development
- A faculty of highly experienced and technical instructors, teaching assistants, and lab assistants providing help around the clock as needed
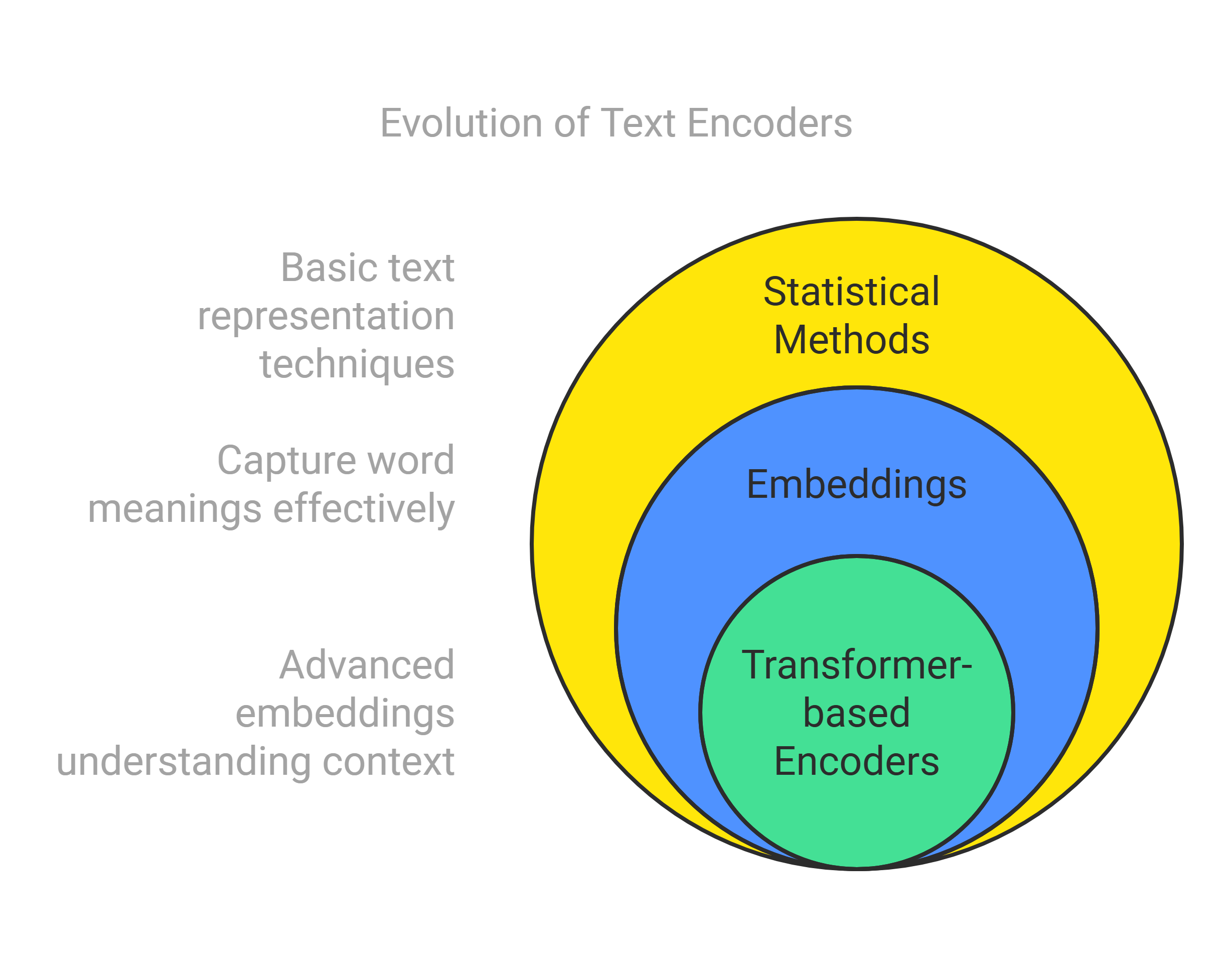
Text encoders have seen an evolution through:
- statistical methods: one-hot-encoders, bag-of-words, TF-IDF
- Embeddings that understand word meanings: word2vec, GLOVE
- Transformer based encoder embeddings: BERT, SBERT
The foundational transformer architectures revolutionising the latest methods for text encoders are covered in some detail along with practical examples of their usage.
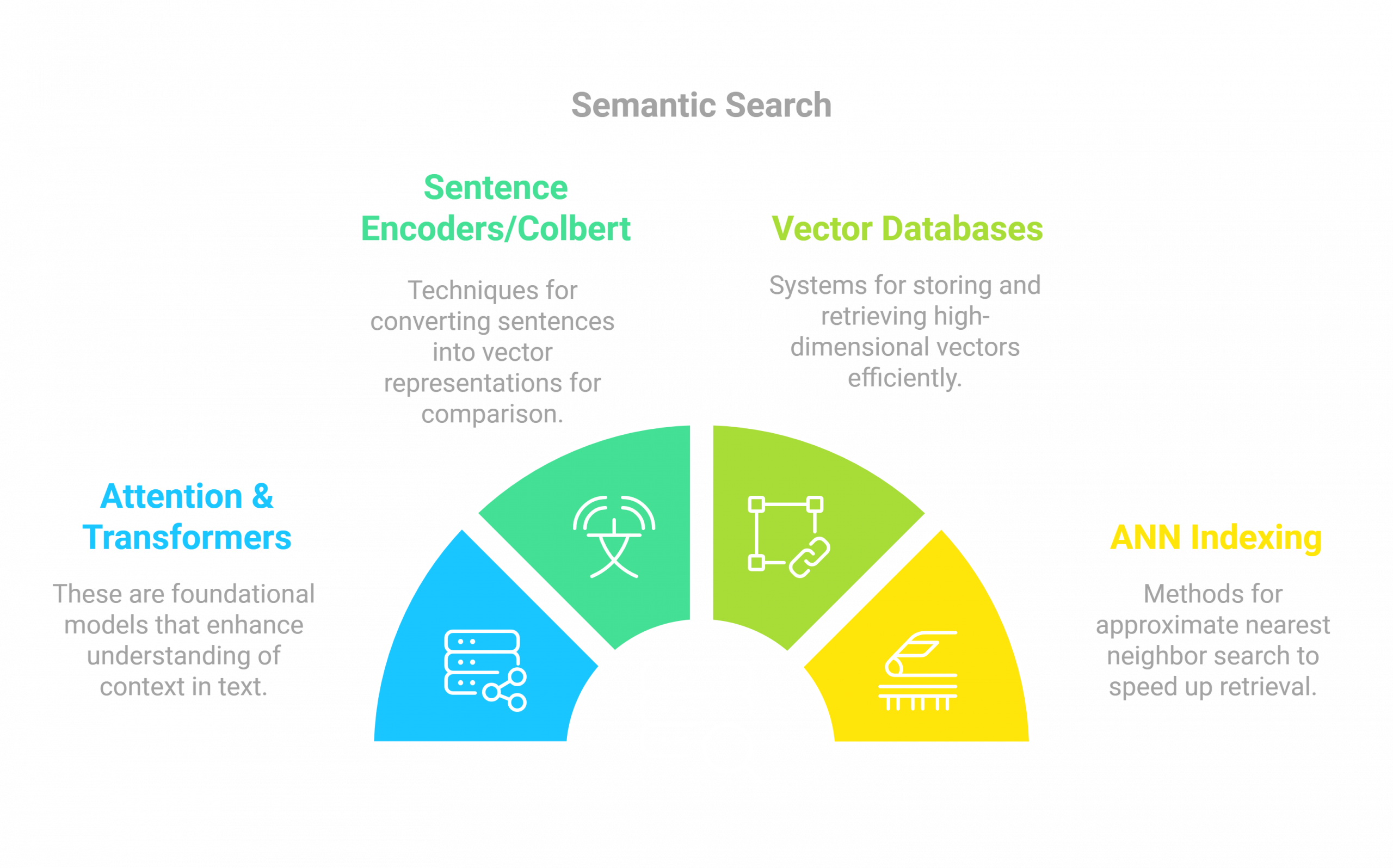
You will learn the concepts underlying semantic search:
- Attention & Transformers
- Sentence Encoders
- Colbert
- Vector databases and ANN indexing approaches
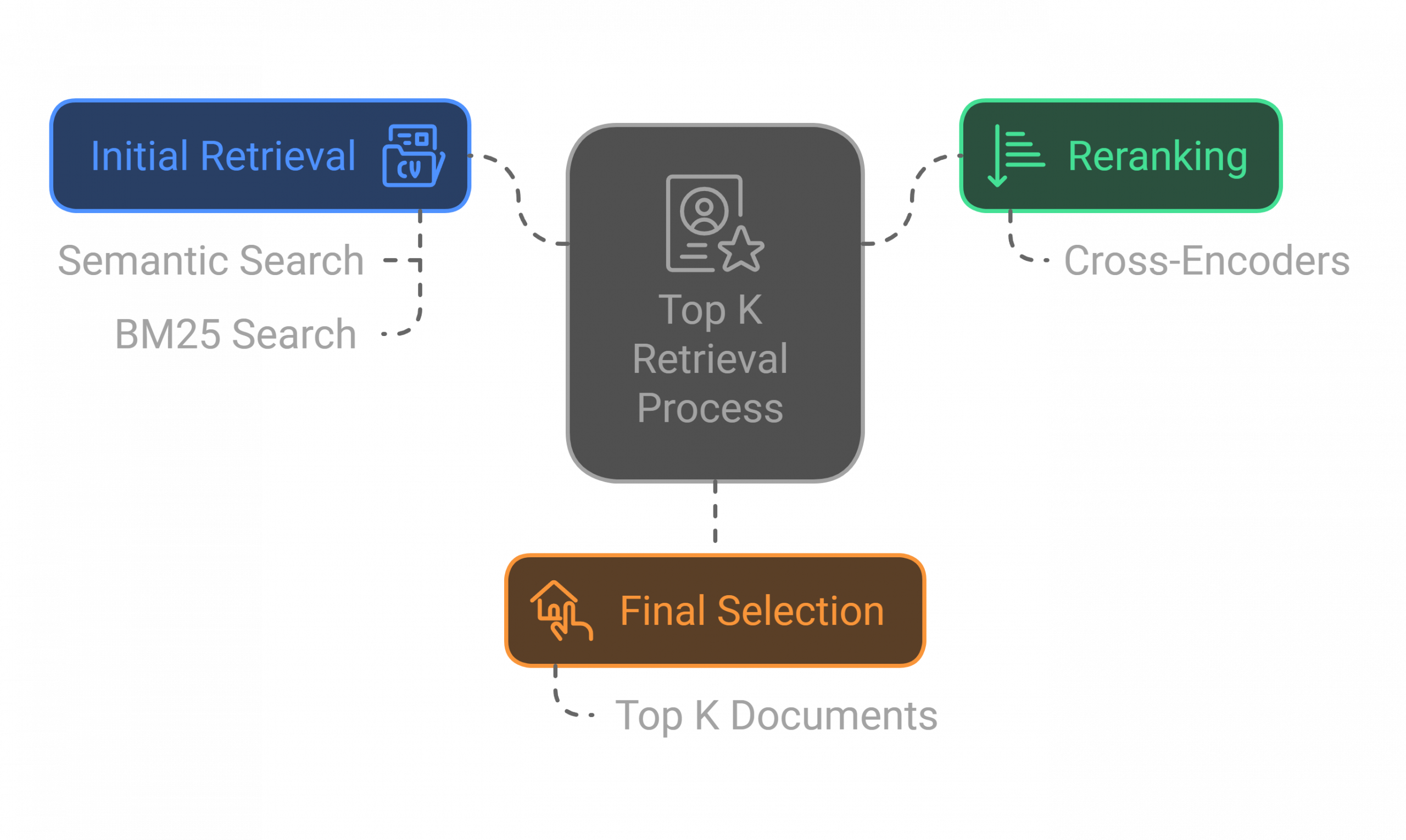
You will learn how to enhance semantic search by integrating with BM25 (keyword) based search and then use cross-encoders to rerank the retrieved results.
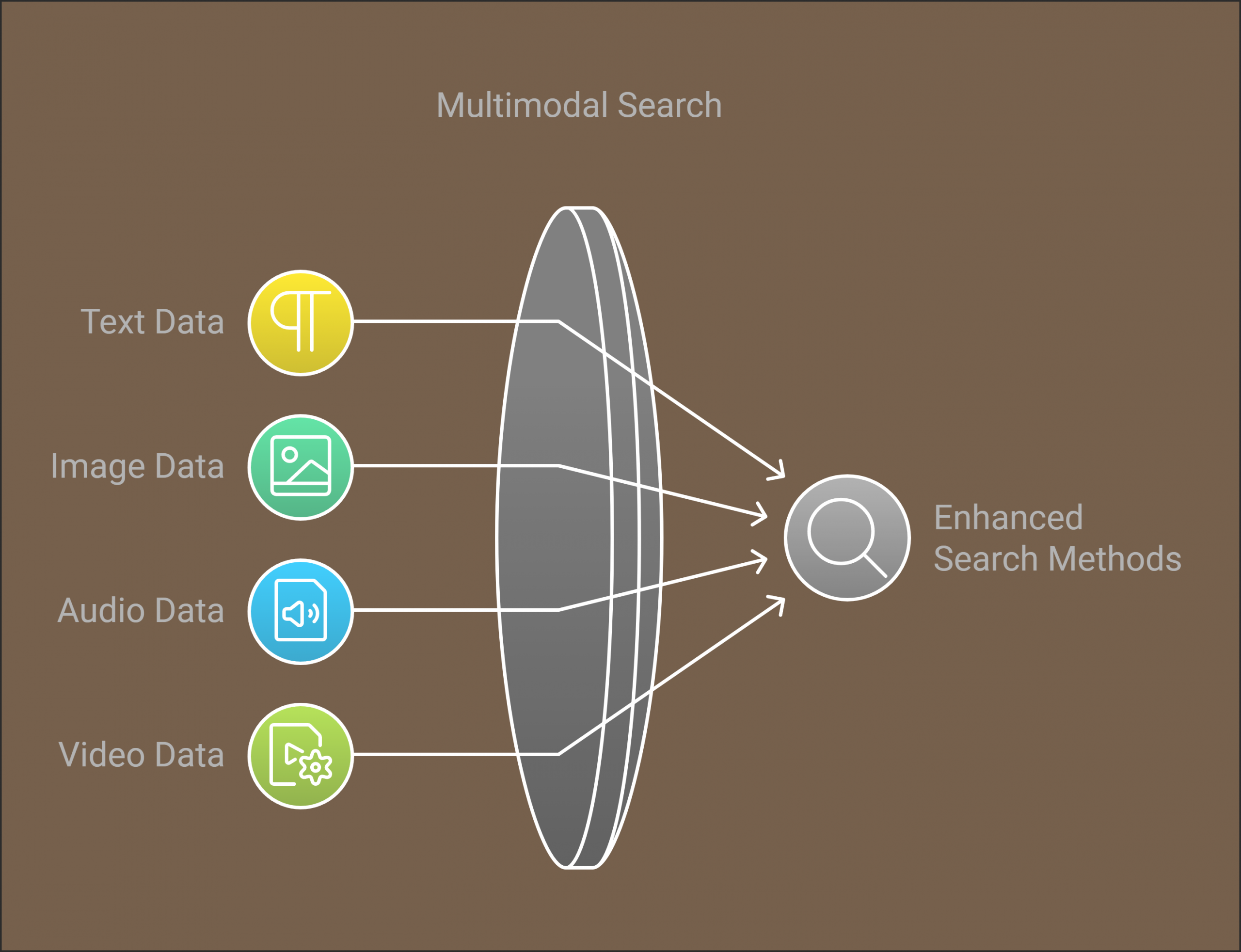
We include non-textual search and retrieval (image, audio, video) through the following multi-modal approaches:
- CLIP
- BLIP-*
- LLaVA
- Auto extractors/Auto-encoders
The goal is to enhance the search and retrieval methods applied to be more broadly applicable with multimodal artifacts and queries.
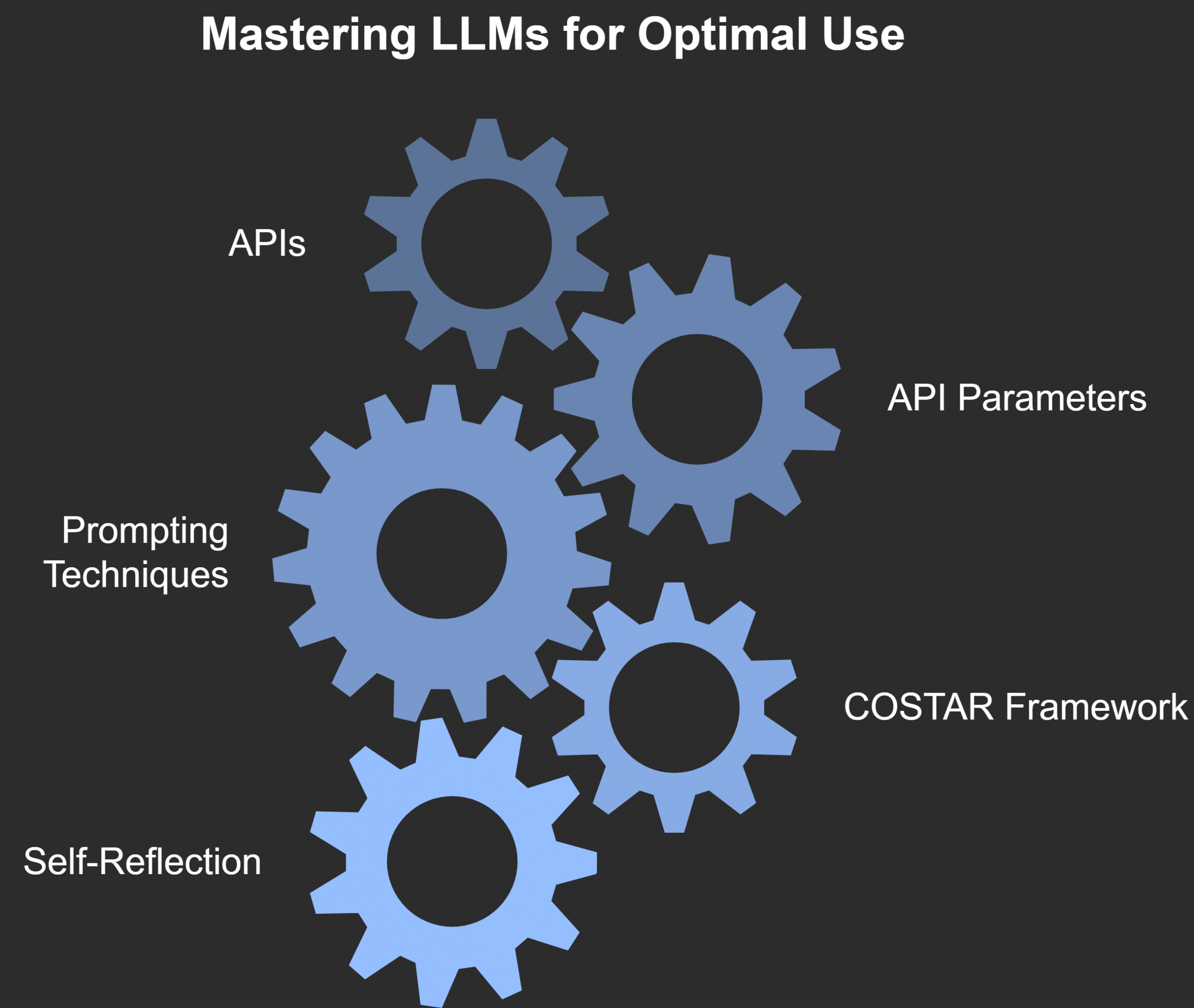
You will learn to get the best out of LLMs using
- Accessing LLMs through APIs
- Understanding the LLM API parameters such as temperature, top p, top k, “nucleus sampling” in softmax
- Prompting techniques
- COSTAR framework
- Self reflection and refine approaches
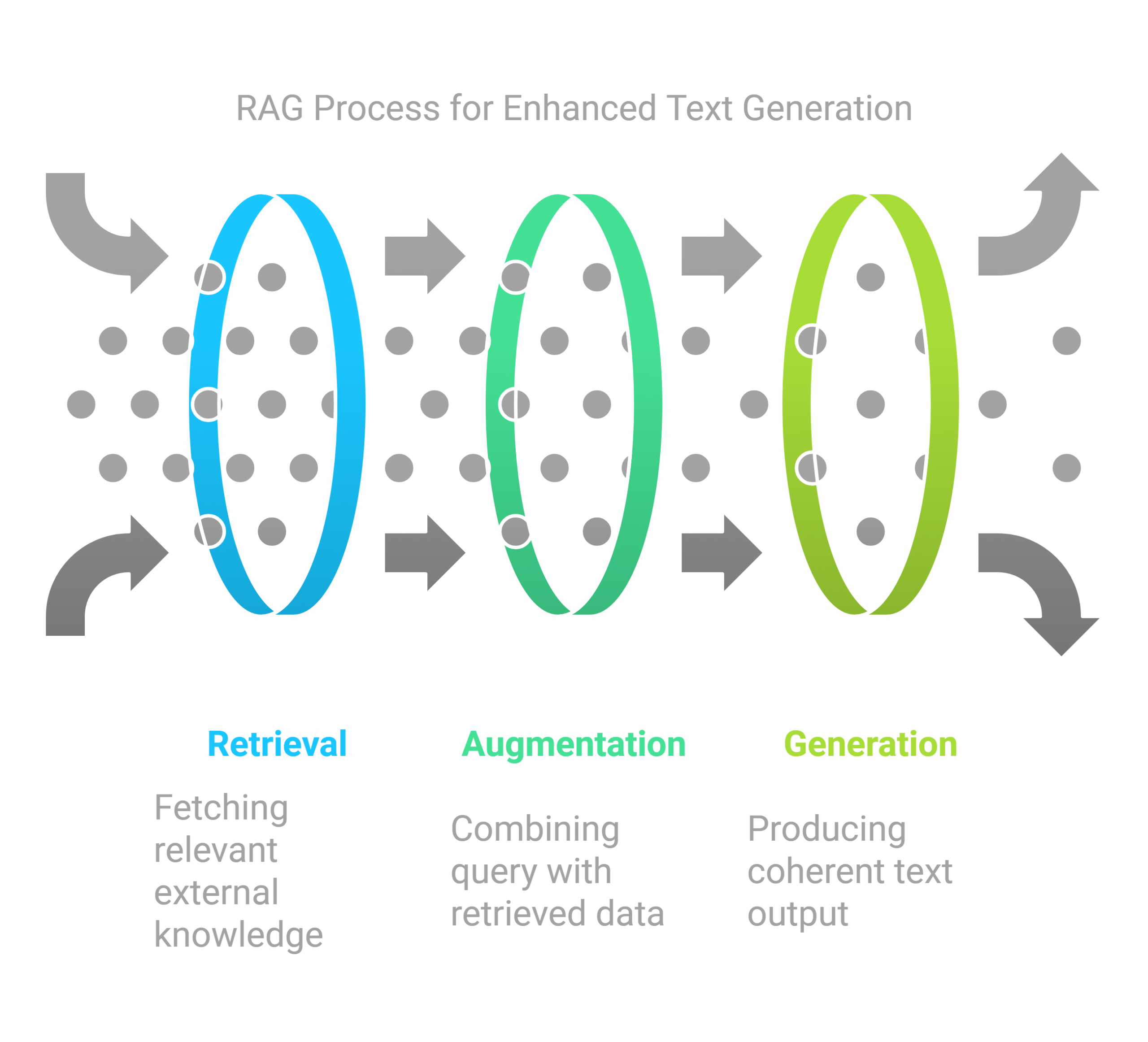
Here you will learn how to put all pieces together by linking the multimodal search engine with an LLM to create what is known as a RAG – retrieval augmented generation.
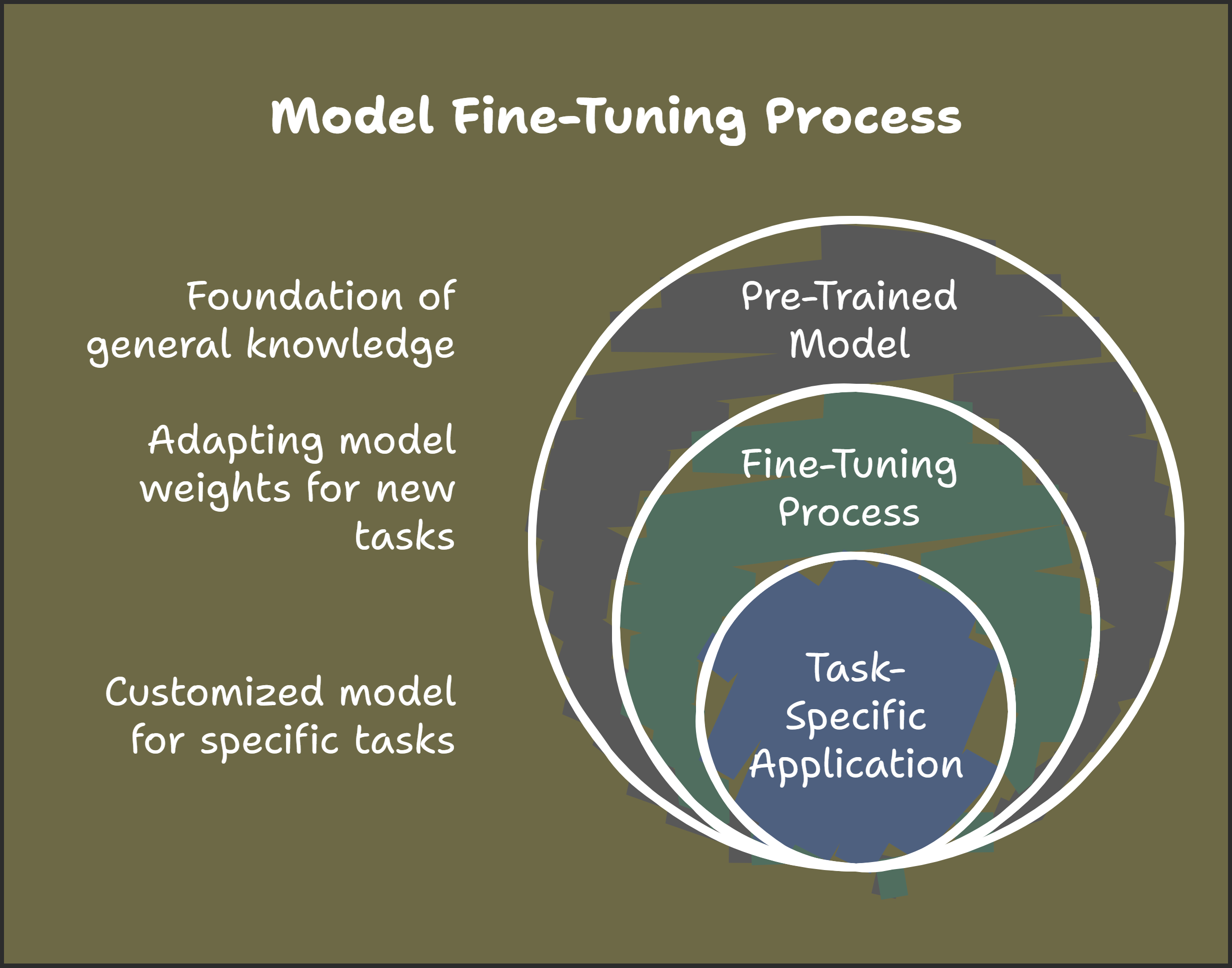
Model fine-tuning is how we can enhance the performance and specificity of AI models on our specific dataset. We will learn and practise some of the fine-tuning best practices and techniques here.

You will gain practical knowledge and insights into AI agent development. In particular, you will learn to build practical multi AI agent applications using the CrewAI framework.
You will learn how you can fine-tune LLMs and/or apply agentic frameworks to handle code generation tasks
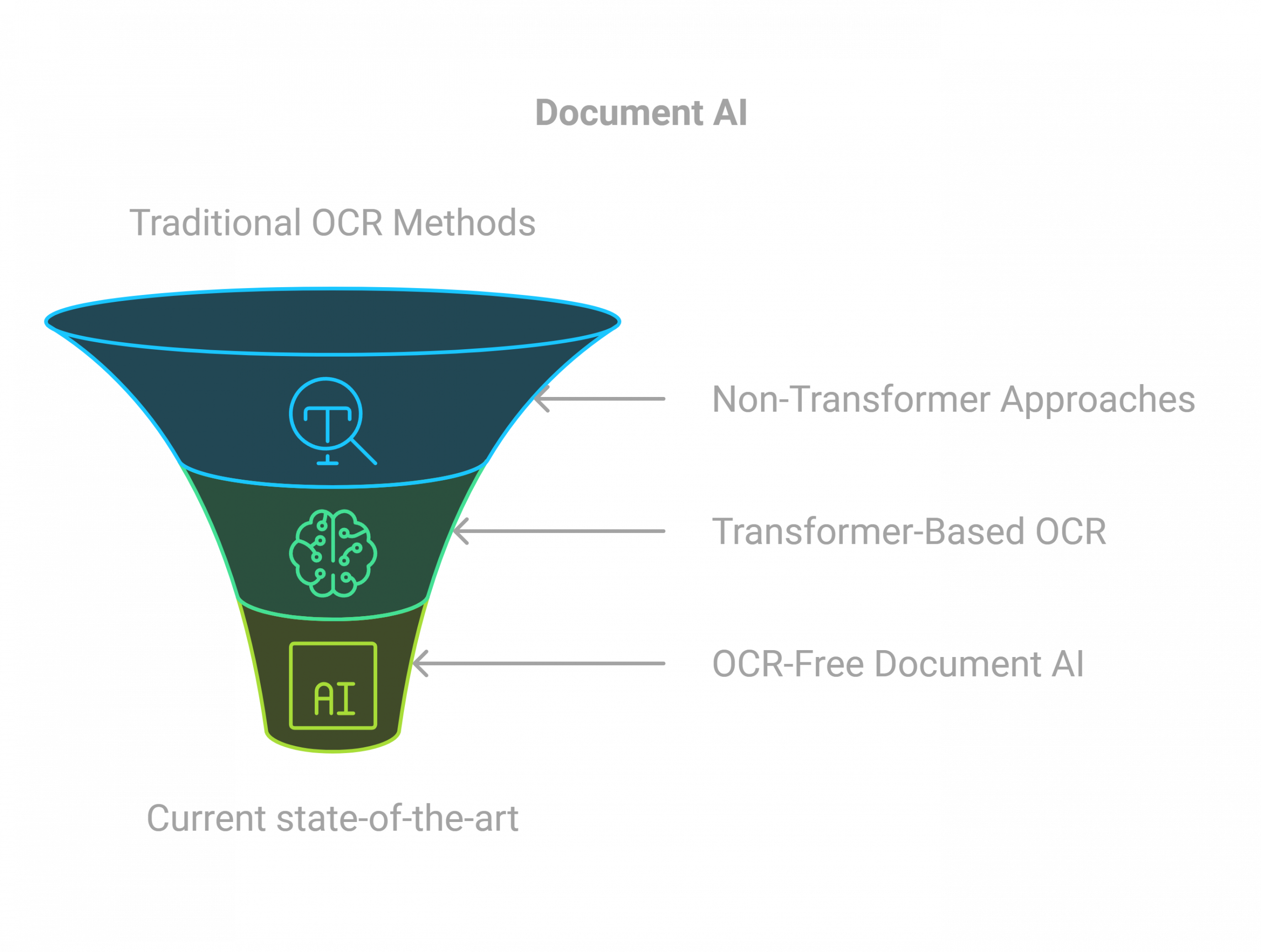
You will learn the latest approaches to what is known as visual language understanding (VLU):
- A recap of older OCR methods
- A comparative study of RCNN, Faster RCNN, Paddle OCR, Tesseract, easy OCR (the non transformer based approaches)
- Transformer based OCR approaches
- OCR free document AI (donut, Nougat, Colpali)
We will go through some important security considerations and their guardrails when using LLMs:
- Adversarial attacks and defenses
- Some open-source approaches – Llamaguard, Promptguard, Guardrails AI
We will go through some of the frontier algorithms used in generative AI to generate high quality images and videos

We will learn usage of some of the SOA models for speech transcription and the reverse process of converting text to speech
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.


