Course Overview
Starting on Monday, Sept 15th, 2025
In today’s technological landscape, mastering Machine Learning Operations (MLOps) and Large Language Model Operations (LLMOps) is essential for driving innovation and efficiency. This course offers a comprehensive exploration of MLOps and LLMOps, equipping participants with the knowledge and skills to streamline workflows, optimize deployments, and ensure robust model management in enterprise settings.
You can attend the course in person or remotely. State-of-the-art facilities and instructional equipment ensure that the learning experience is invariant of either choice. Of course, you can also mix the two modes: attend the course in person when you can, and attend it remotely when you cannot. All sessions are live-streamed and recorded and available on the course portal.
Learning Outcome
By the end of this course, participants will be equipped to implement MLOps and LLMOps effectively, enhancing the efficiency, scalability, and security of their machine-learning workflows and driving greater value in their enterprise settings.
Schedule
| START DATE | MONDAY, Sept 15th, 2025 |
|---|---|
| Periodicity | Meets every Monday and Wednesday evening. |
| Schedule | 7 PM to 10 PM PST |
| Lectures | Monday evening sessions |
| Labs | Wednesday evening sessions |
| End Date | Wednesday, March 25th, 2025 |
Call us at 1.855.LEARN.AI for more information.
Skills You Will Learn
MLOps Fundamentals, LLM Deployment, Pipeline Automation, Monitoring and Logging, Scalable Inference
Prerequisites

Syllabus details
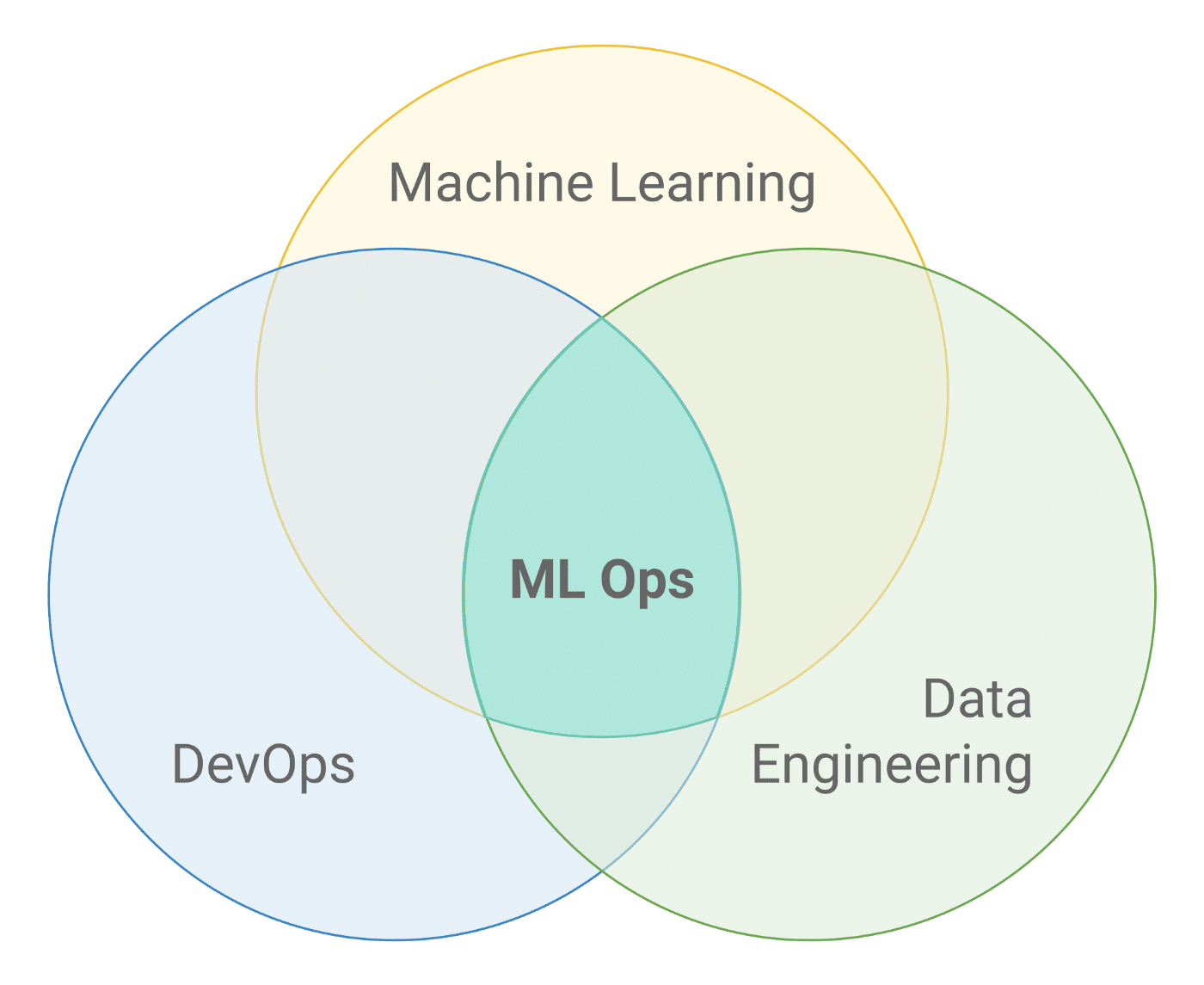 Course Topics:
Course Topics:
- What is MLOps and why does it matter?MLOps involves deploying and maintaining machine learning models in production reliably and efficiently. It bridges data science and operations, enhancing operational efficiency and model scalability.
- What is LLMOps?LLMOps extends MLOps principles to large language models, focusing on model fine-tuning, efficient inference, and handling computational requirements.
- MLOps Architecture and WorkflowsUnderstand key components of MLOps architecture, including data pipelines, model training workflows, and deployment strategies. Learn about tools like Jenkins, Airflow, MLFlow, Kyte, and Kubeflow.
- KubernetesLearn Kubernetes fundamentals for managing containerized applications and deploying machine learning models at scale.
- Feature Stores and Model ManagementExplore the role of feature stores in managing features and best practices for model management and storage, ensuring versioning and reproducibility.
- Ray FrameworkDiscover the Ray framework for scaling machine learning applications, including Ray Data, Ray Train, and Ray Serve.
- Scalable Model InferenceKey considerations in designing scalable inference serving solutions, optimizing performance, and managing resources.
- NVidia Triton and TensorRTLeverage NVidia Triton and TensorRT for efficient model inference serving in resource-intensive scenarios.
- ObservabilityImplement best practices for monitoring, logging, and metrics tracking to maintain model health and performance.
- Model SecurityEnsure model security with tools like LlamaGuard, focusing on threat detection and vulnerability assessment.
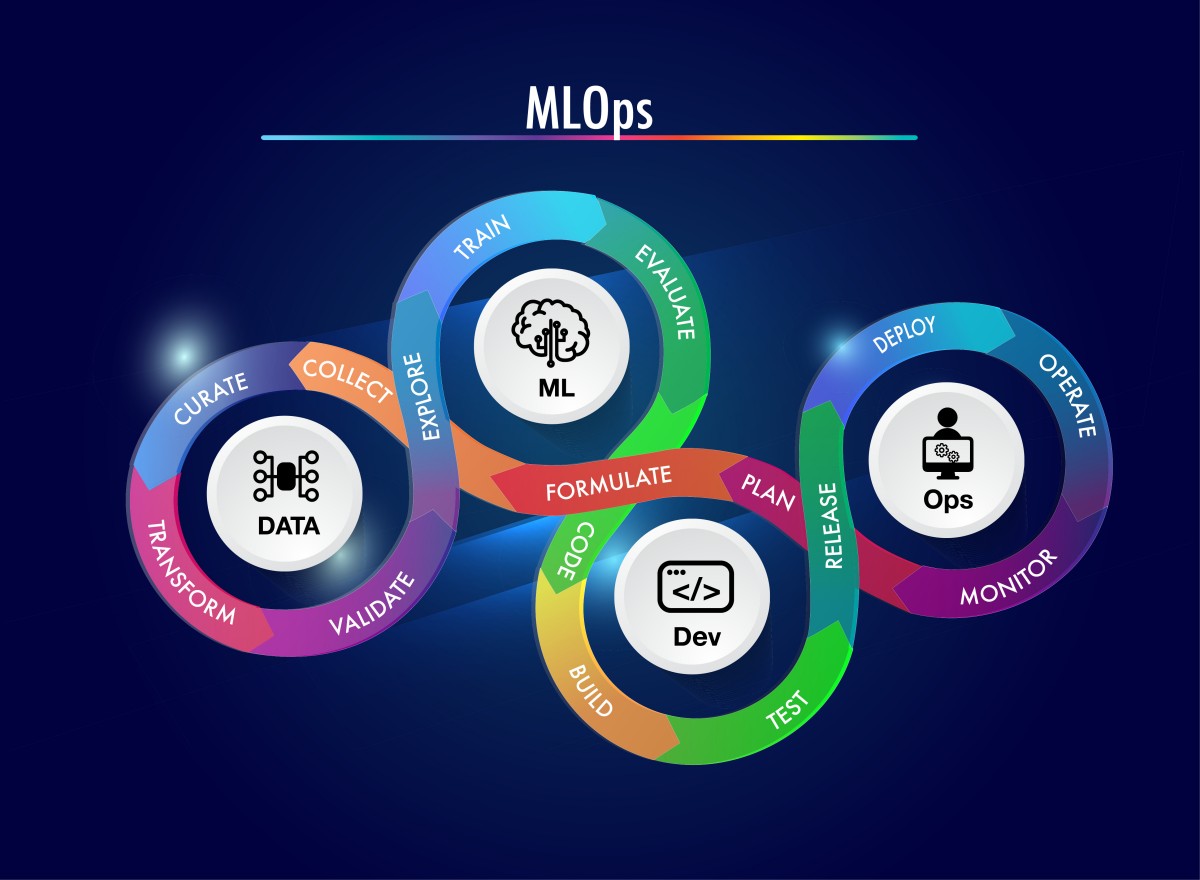
In this session, we will cover the following topics:
- Course Overview and Structure: Understand the key objectives and outline of the course, including how the sessions are designed to balance theory, practical implementation, and industry use cases. Learn the expectations and deliverables for successful completion.
- Core Concepts in MLOps: Explore the foundational principles of MLOps, focusing on automating machine learning workflows, reproducibility, and managing models in production environments.
- MLOps vs. LLMOps: Examine the unique challenges of working with large language models in production compared to traditional machine learning models. Gain insights into why LLMOps is emerging as a specialized subfield, addressing issues like model size, latency, and inference scalability.
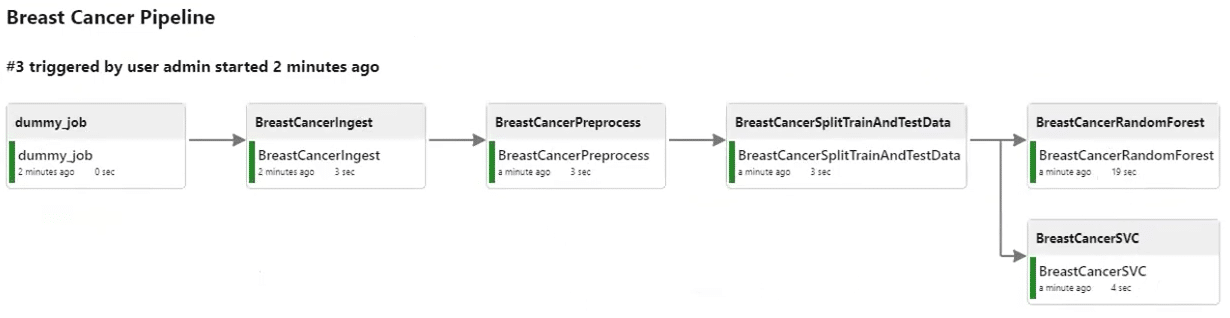
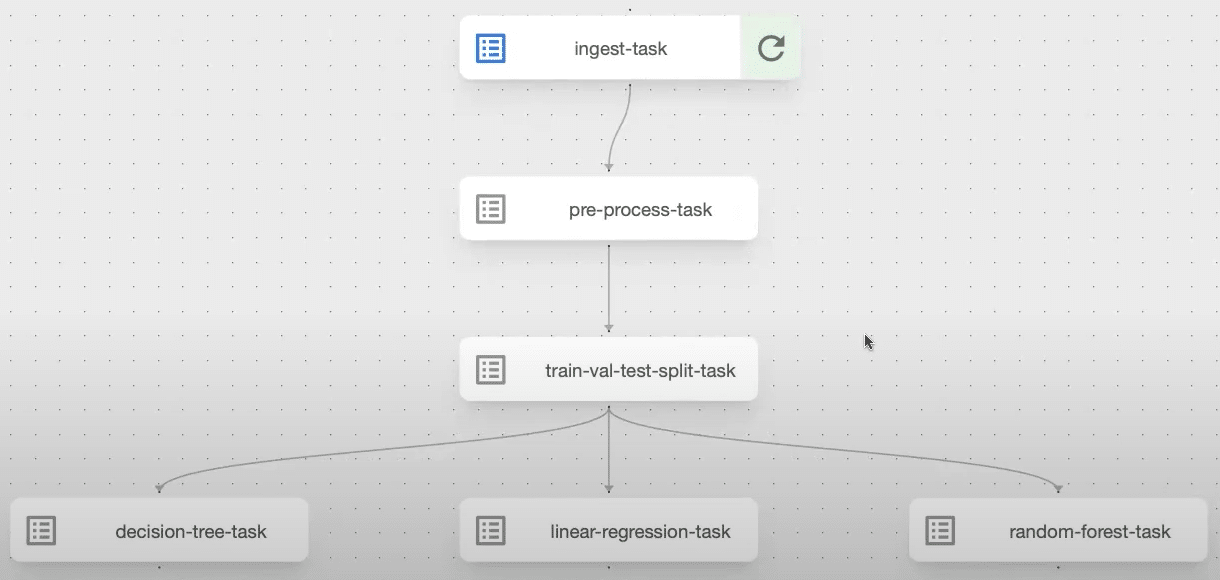
In this session, we will cover the following topics:
- Kubeflow Pipeline Setup: Learn to design and implement end-to-end machine learning workflows using Kubeflow, including defining components, orchestrating tasks, and monitoring pipeline execution.
- Airflow Pipeline Setup: Understand how to create and schedule ML pipelines with Apache Airflow, focusing on DAG creation, task dependencies, and integrating ML tasks for efficient workflow automation.

In this session, we will cover the following topics:
Part 1: Presentation on AI Trends and Enterprise Applications
- Explore the latest advancements in AI and their relevance to large-scale enterprise use cases, highlighting innovations in model architectures, deployment strategies, and integration into business workflows.
Part 2: MLflow in the MLOps Ecosystem
- Discuss MLflow’s role in the MLOps lifecycle, focusing on how it streamlines data preprocessing, model training, deployment, and monitoring within enterprise-scale workflows.
- Understand its capabilities for experiment tracking, reproducibility, and model versioning, ensuring efficient collaboration and scalability.

In this session, we will cover the following topics:
- Assignment Solutions: Detailed walkthrough of the solutions for the first two assignments, addressing key concepts, common challenges, and best practices.
- MLflow Pipeline Discussion: Explore the design and implementation of an MLflow pipeline, focusing on its components for tracking experiments, managing model lifecycle, and integrating with deployment workflows.
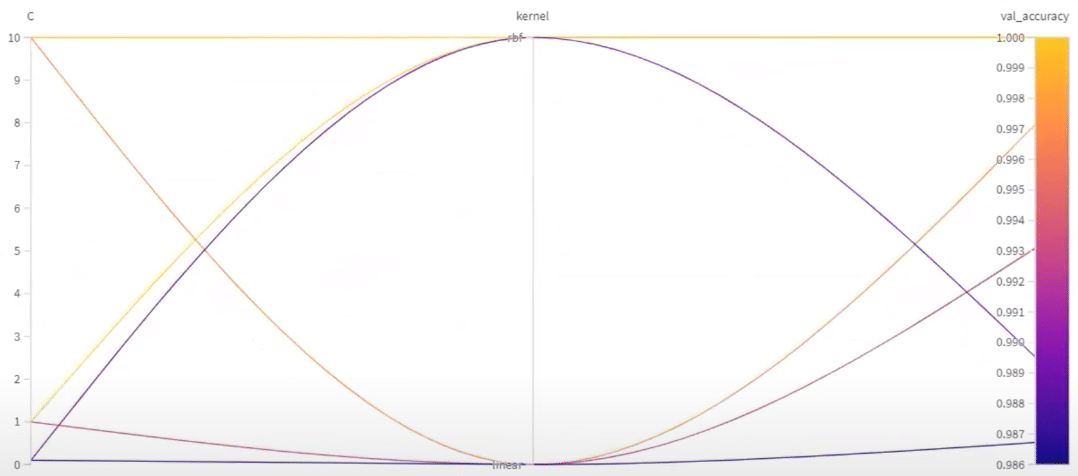
In this session, we will cover the following topics:
- Weights & Biases Pipeline Setup: Step-by-step guide to setting up and configuring Weights & Biases for experiment tracking and model management in MLOps workflows.
- Neptune Pipeline Setup: Overview of integrating Neptune for tracking machine learning experiments, visualizing metrics, and collaborating on model development.
- Alternate Approach for Airflow Pipeline Setup: Explore a different method for configuring and optimizing Airflow pipelines for scalable ML workflows.
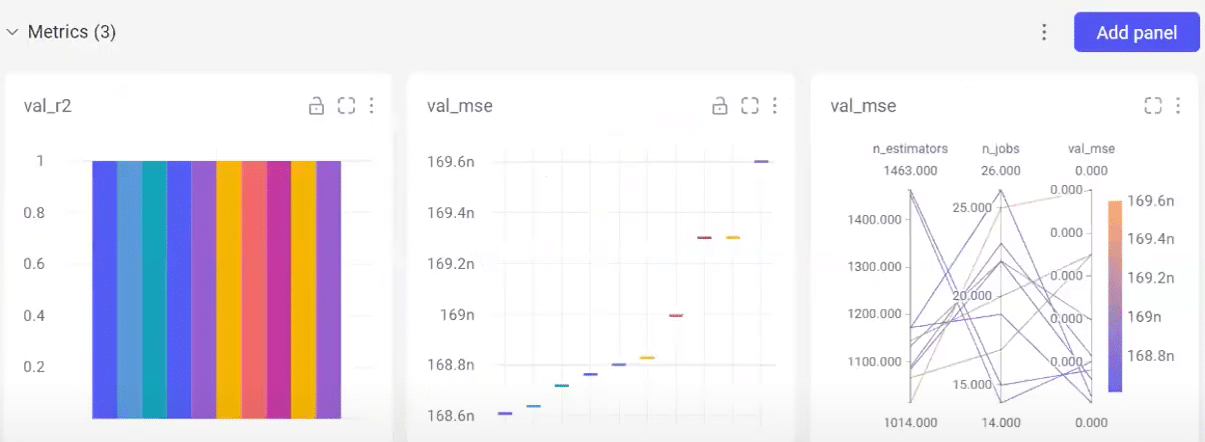
In this lab session, we will cover the following topics:
- Comet ML Setup and Integration: A hands-on guide to setting up Comet ML for experiment tracking, including configuration and integration into your existing MLOps workflows.
- Optimizing ML Experiments with Comet ML: Learn how to use Comet ML’s features to monitor, visualize, and optimize your machine learning experiments for better performance and reproducibility.
 In this session, we will cover the following topics:
In this session, we will cover the following topics:
- Key Concepts of Distributed Computing: An overview of the fundamental principles behind distributed computing, focusing on scalability and resource optimization.
- Introduction to Ray: Introduction to Ray, a framework for distributed computing that simplifies scaling machine learning workflows.
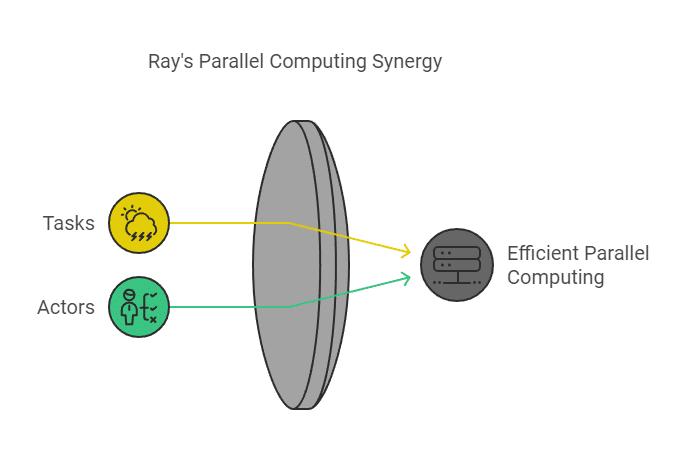
- Ray Tasks and Actors: Learn how Ray tasks and actors work for parallel computing and resource management in distributed environments.
- Asynchronous Processing and Task Scheduling: Explore how asynchronous processing and task scheduling enhance computational efficiency and throughput.
- Use Case: Named Entity Recognition (NER): A practical demonstration of using Ray in a Named Entity Recognition (NER) task, showcasing its scalability and performance improvements.
 In this lab session, we will cover the following topics:
In this lab session, we will cover the following topics:
- Task Overview: Participants will be provided with a zip file containing six books by Leo Tolstoy, where each chapter is an individual text file.
- Named Entity Recognition (NER): We will perform NER on the chapters to identify people, places, and organizations.
- Data Processing: Participants will preprocess the text data, applying NER models to extract and classify entities.
- CSV Compilation: The recognized entities (people, places, organizations) will be compiled into a structured CSV file for easy analysis and reference.
In this session, we will cover the following topics:
- Distributed Computing Challenges & Ray Framework:
- Discussion on the challenges in distributed computing.
- Overview of the Ray framework, focusing on task distribution and memory management.
- Introduction to Ray Data and its optimization for machine learning datasets.
- Comparison with Spark and Real-World Use Cases:
- Comparison of Ray Data with Spark, highlighting its advantages in GPU utilization and better integration with machine learning tools.
- Exploration of Ray Data’s Pandas-like API for data shuffling efficiency.
- Examination of Ray Data’s adoption in real-world companies like ByteDance and Spotify.
In this lab session, we will cover the following:
- MLflow Integration:
- Integration of MLflow for model training, hyperparameter tuning, and serving models using the California Housing dataset.
- MLflow Setup Demo:
- Demonstration of MLflow setup, model registry, and the differences between local and cloud-based model saving.
- Parallel Processing and Troubleshooting:
- Discuss techniques like text chunking, clustering, and address system configuration issues to improve parallel processing efficiency.
In this lab session, we will cover the following topics:
- Text Classification: Techniques and best practices for training text classification models.
- Distributing Training with Ray Train: Utilizing Ray Train for distributed training to accelerate model training processes.
- Using Hugging Face Trainer: Simplifying model training using Hugging Face Trainer, integrating it with Ray for better scalability.
- vLLM for Scalable LLM Deployment: Learn how vLLM uses page attention to optimize memory and GPU usage, enabling high-throughput, multi-user support.
- Operating Modes: Explore batch mode for Python scripts and server mode for external client interaction via endpoints.
- Hardware Considerations: Understand the hardware needs for larger models, ideal for production, and compare vLLM with Ollama for smaller setups.
In the final session, we cover the following topics:
- Course Recap: A brief review of key concepts covered throughout the course.
- MLOps Overview: A comprehensive understanding of MLOps practices and their importance in managing the machine learning lifecycle.
- Emerging Trends and Concepts: Explore the latest advancements in MLOps and LLMOps, including new tools, techniques, and frameworks.
- Challenges in MLOps and LLMOps: Discuss the common hurdles faced when implementing MLOps and LLMOps, such as scaling, model monitoring, and data management.
- Practical Considerations in MLOps: Focus on real-world challenges and best practices for deploying, managing, and maintaining ML models in production.
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.

Krishnan Ramaswamy
Co-Instructor
Background
Krishnan Ramaswamy is an engineering leader, AI practitioner, and educator with an M.S. in Computer Science and Engineering and more than 25 years of industry experience. Throughout his career, he has designed and delivered large-scale platforms, enterprise applications, and AI/ML-driven solutions across Collaboration, Security, and Customer Experience domains. His expertise includes AI engineering, large language models, retrieval systems, agent architectures, distributed systems, and enterprise platform development. He is passionate about transforming emerging research into production-ready solutions that deliver measurable business value.
Educator
As a co-instructor at SupportVectors, Krishnan mentors engineers and technology professionals on modern AI engineering practices, helping them understand not only how AI systems are built, but also how they can be deployed, evaluated, governed, and scaled in enterprise environments. His teaching combines deep technical knowledge with real-world experience gained from decades of building and leading engineering initiatives.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.

