Course Overview
Starting on Sunday Morning, June 07, 2026
An eagerly awaited twelve-week course on AI Agents and fine-tuning. Includes multiple
agents, agentic communications, supervised fine-tuning and reinforcement learning. The last two weeks are reserved for capstone work and presentations
The teaching faculty for this workshop comprises the instructor, a supportive staff of teaching assistants, and a workshop coordinator. Together they facilitate learning through close guidance and 1-1 sessions when needed.
You can attend the workshop in person or remotely. State-of-the-art facilities and instructional equipment ensure that the learning experience is invariant of either choice. Of course, you can also mix the two modes: attend the workshop in person when you can, and attend it remotely when you cannot. All sessions are live-streamed, as well as recorded and available on the workshop portal.
Learning Outcome
By the end of the AI Agents and Advanced Fine-Tuning Bootcamp , participants will master the core design patterns to engineer effective, practical, real-world AI agents driven applications. You will have learned techniques to build and optimize high-performance and robust AI agentic solutions. You will gain hands-on experience through labs and real-world use-case driven projects, developing the skills and confidence to solve complex challenges and showcase a strong portfolio.
Schedule
| Start Date | SUNDAY, June 07, 2026 |
|---|---|
| Duration | 12 weeks |
| Session days | Every Sundays |
| Session timing | 11 AM PST to Evening |
| Session type | In-person/Remote |
| Morning sessions | Theory/Paper Readings |
| Evening sessions | Lab/Presentation |
| LAB Walkthrough |
Tuesday, 7 PM to 10 PM (Summary and Quiz) Wednesday, 7 PM to 10 PM (Lab) |
Call us at 1.855.LEARN.AI for more information.
Skills You Will Learn
Hands-on AI Agents and advanced fine-tuning of LLMs using SFT and Reinforcement Learning, focused on real-world, production-grade deployment.
Prerequisites
Focus
A 12-week bootcamp designed to deep dive into the world of AI Agents and fine-tuning. This curriculum spans both the theoretical foundations and the practical engineering realities of building advanced, scalable AI systems.
What Will Be Covered
- AI Agents & Architecture: Foundations of the agentic loop, enterprise workflows, and implementing core agentic design patterns (including Agentic RAG and multi-turn training).
- Tooling & Optimization: Integrating tools via the Model Context Protocol (MCP) and mastering programmatic prompt optimization using DSPy and evolutionary algorithms (GEPA, ORPO, TextGrad).
- Fine-Tuning & RL: The mechanics of model adaptation using PEFT (LoRA, qLoRA) and aligning models with Reinforcement Learning (PPO, DPO, GRPO).
- Multi-Agent Systems & Scalability: Architecting inter-agent communications (A2A), resolving uncertainties, and scaling MLOps pipelines using the Ray framework.
Lab
- General Lab Environment setup and access configuration for the Ray Cluster.
Focus
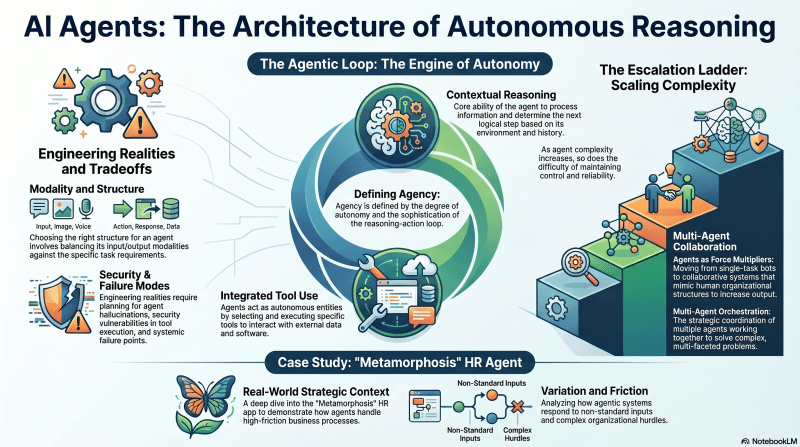
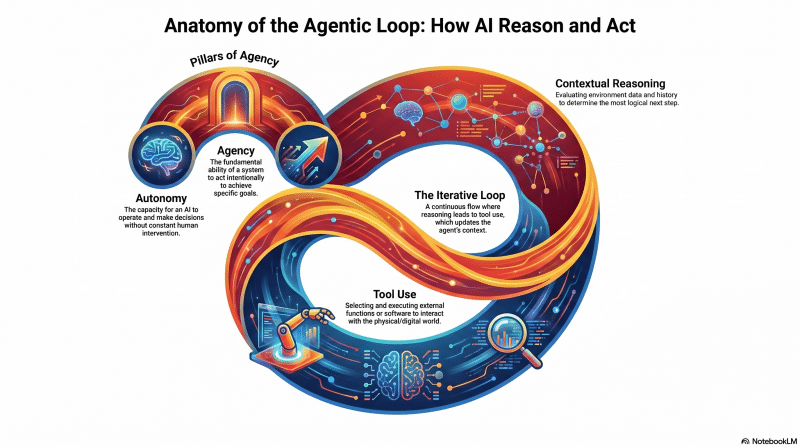
Understanding the fundamental concept of AI agents, their structure, historical context, and the core agentic loop that drives autonomous reasoning and tool use.
Key Takeaways
- The Concept of an Agent: Historical aspirations, human intelligence, and agents as force multipliers.
- The Agentic Loop: Defining agency, autonomy, contextual reasoning, and tool use.
- Structure and Tradeoffs: The modality of agents, the escalation ladder, and engineering realities (including security and failure modes).
- Demo Analysis: Deep dive into “Metamorphosis” (HR Agentic App), analyzing variation, friction, and the strategic context of the agentic moment.
Lab
- Environment setup and Lab environment configuration
- Accessing the Ray Cluster
- Hands-on: Introduction to AI Agents using n8n
Focus
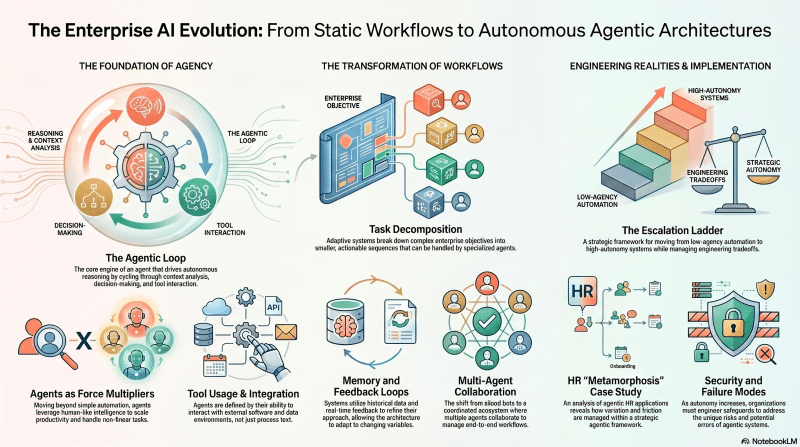
Exploring the evolution of enterprise software toward autonomous reasoning, the economics of agentic systems, and the core rubric for defining and evaluating agentic behavior in production.
Key Takeaways
- Evolution of Workflows: The promise of autonomous reasoning, microservices vs. agency, and the tool-use maximalist perspective.
- Core Rubric of Behavior: Planning, task decomposition, coordination, critique, reflection, and the vital role of memory.
- Empowerment Through Tools: Introduction to the Model Context Protocol (MCP) and physical AI (ambient agents).
- Sociology of Multi-Agent Teams: Game theory, Shapley values, harmony vs. the “Betta Fish” problem, and case studies (e.g., Smallville).
- Agentic RAG: The shift from linear to agentic retrieval-augmented generation.
Lab
- Google ADK Basics
- LangGraph Basics
Focus
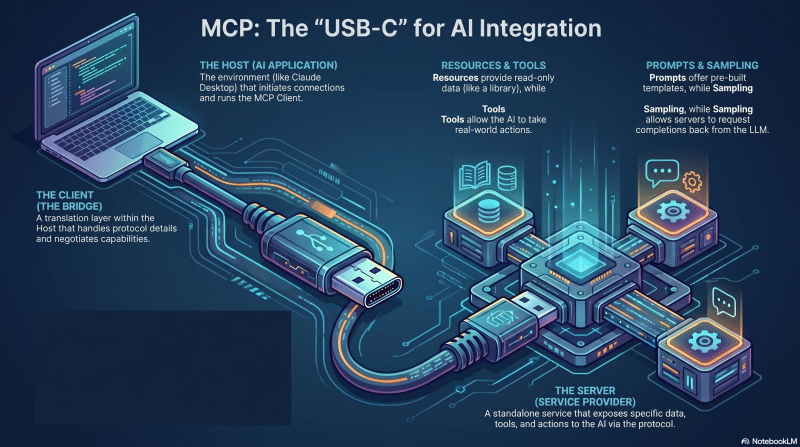
The fundamental concept of tools and the case for the Model Context Protocol (MCP) as an unopinionated standard for connecting AI models to data sources and execution environments.
Key Takeaways
- MCP Architecture: The evolution of tool use, the tool server (FastMCP), the agent client (Google ADK), and the abstraction layer.
- Tool Craft: Building reliable MCP tools, proper instructions, documentation, and managing tool execution logic.
- A New Programming Philosophy: The primacy of the tool library, the tool-use maximalist pattern, and orchestration via runners.
- Case Studies: Code walkthrough of a Customer Service Agent and the “Broken Item” scenario.
Lab
- Google ADK Basics – continuation with MCP
- Google ADK MCP OAuth
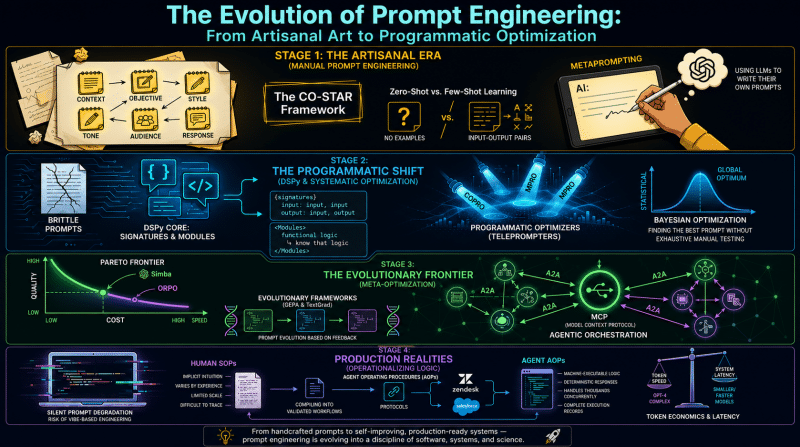
Focus
Mastering the art of steering foundational models from basic prompt engineering and mitigating epistemic uncertainty to programmatic prompt optimization using DSPy and evolutionary frameworks.
Key Takeaways
- Prompt Engineering Basics: CO-STAR framework, zero-shot vs. few-shot, mitigating hallucinations, and metaprompting.
- Programmatic Optimization: Using DSPy (Signatures, Modules, Optimizers), COPRO, MIPRO, and Bayesian optimization in joint spaces.
- Evolutionary Frameworks: GEPA (Genetic-Pareto), TextGrad, ORPO, Simba, and the Pareto Frontier of engineering trade-offs.
- Production Realities: Navigating silent prompt degradation, system latency, token economics, and model routing.
Lab
- Advanced Prompting Techniques
- DSPy Basics
- DSPy Optimizers
Focus
The operational landscape of model adaptation, transitioning from the physics of semantic embeddings and contrastive loss to parameter-efficient fine-tuning strategies.
Key Takeaways
- Foundational Geometry: The curse of dimensionality, anisotropy to isotropy, and contrastive loss functions (Triplet Loss, InfoNCE, SimCLR).
- Scaling and Constraints: Chinchilla scaling laws, epistemic error, simplicity bias, and the hardware bottleneck.
- Economy Fine-Tuning (PEFT): The mathematics of LoRA, rank allocation, and quantization.
- Advanced Steering: Soft prompting, continuous steering vectors, prefix tuning, and activation modulation.
Lab
- Contrastive fine-tuning of text embedders and visualization
- Fine-tuning methods: Full fine-tuning, LoRA, and qLoRA
- Comparison with baseline models
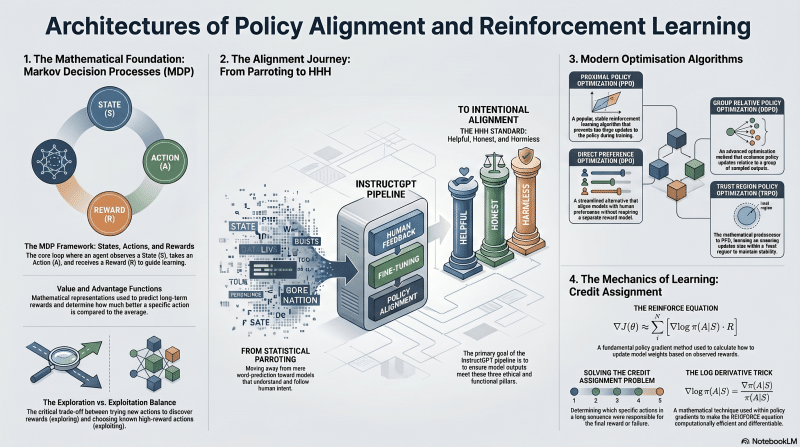
Focus
Transitioning from supervised learning to the mathematical framework of Reinforcement Learning (RL), focusing on aligning models through policy gradients, reward functions, and modern optimization algorithms.
Key Takeaways
- RL Mathematical Framework: Markov Decision Processes (MDP), states, actions, rewards, the value function, and the advantage function.
- The Alignment Problem: Moving from statistical parroting to Helpful, Honest, and Harmless (InstructGPT pipeline).
- Modern Algorithms: Deep dive into TRPO, PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), and GRPO (Group Relative Policy Optimization).
- Credit Assignment: The REINFORCE equation, exploring vs. exploiting, and the log derivative trick.
Lab
- RL grid problem
- PPO grid problem
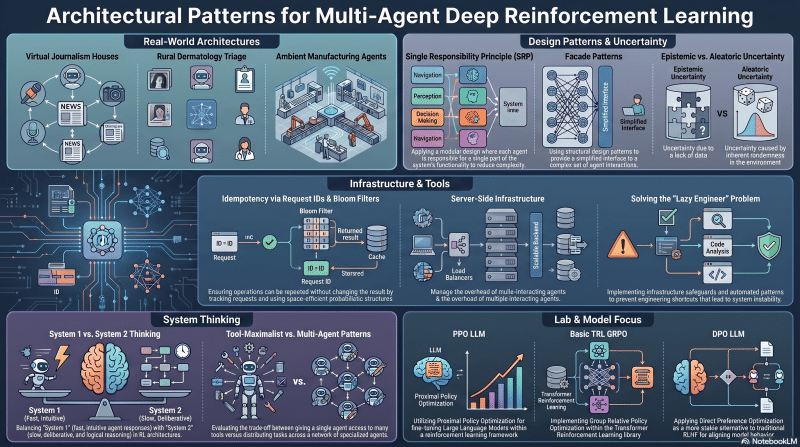
Focus
Expanding RL theory to large language models while concurrently addressing the engineering patterns, uncertainties, and architectural strategies required to manage multiple interacting agents.
Key Takeaways
- Broader Use Cases: Real-world architectures like Virtual Journalism Houses, Rural Dermatology Triage, and Ambient Manufacturing Agents.
- Design Patterns: Single Responsibility Principle (SRP), Facades, and managing epistemic vs. aleatoric uncertainty.
- Tooling Infrastructure: Idempotency (Request IDs, Bloom filters), server-side infrastructure, and handling the “Lazy Engineer” problem.
- System Thinking: System 1 vs. System 2 thinking, and the “Tool-Maximalist” vs. “Multi-Agent” patterns.
Lab
- PPO LLM
- Basic TRL GRPO
- DPO LLM
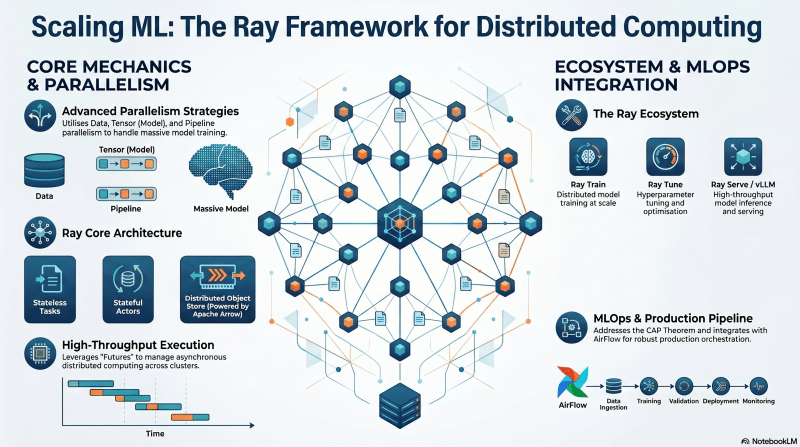
Focus
The physics of distributed computing and how the Ray framework enables massive model training, tuning, and high-throughput inference across clusters.
Key Takeaways
- Parallelism Strategies: Data, Tensor (Model), and Pipeline parallelism.
- Ray Core Mechanics: Ray Tasks (stateless), Ray Actors (stateful), Futures, and the Distributed Object Store (Apache Arrow).
- Ecosystem Integration: Distributed orchestration with Ray Train, optimization via Ray Tune, and inference with Ray Serve and vLLM.
- MLOps vs DevOps: The CAP Theorem, managing hyperparameters, data ingestion, and building production pipelines.
Lab
- Dealing with Batched Inference with Observability
- MLOps pipeline (AirFlow)
Focus
Architecting Inter-Agent Communication (A2A) protocols at an internet-scale, tackling the challenges of discovery, authentication, and state management in distributed agent ecosystems.
Key Takeaways
- Communication Paradigms: Agent personalities, debate structures, consensus building, and the N^2 communication explosion.
- A2A Protocols: Designing the Agent Card (capabilities, constraints, expectations), discovery mechanisms, and real-world standards (Nanda, Cisco Agency).
- Security & State: Distinguishing AuthN from AuthZ, role-based access control, and state maintenance.
- Cooperation Protocols: Role-based, voting-based, and debate-based cooperation.
Lab
- Ray core and Ray data
- A2A with G-ADK

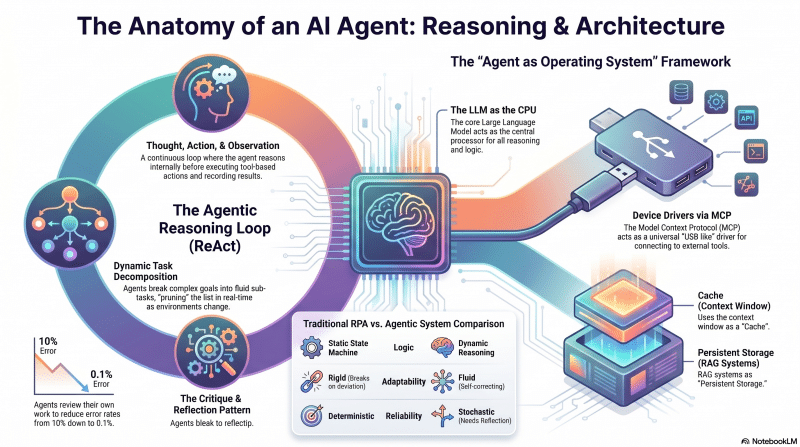
Focus
Consolidating enterprise patterns into a comprehensive architecture, exploring the OSI model for agents, and mastering the nine distinct agentic design patterns for production systems.
Key Takeaways
- Agentic OSI Model: Tool Integration (MCP), Collaboration (A2A), Frameworks (ADK), Infrastructure (Agency), and Discovery (NANDA).
- Agentic Design Patterns: Sequential pipelines, Router/Dispatcher, Parallel Fan-Out/Fan-In, Orchestrator-Workers, Evaluator-Optimizer, Group Chat/Council, Dynamic Handoff, Task Ledger, and State Machines.
- System Reliability: The Doctrine of Ruthless Simplification, avoiding unique dysfunctions, and navigating the exploration vs. exploitation trade-off.
Lab
- A2A with LangGraph
- Agent Registry
- Agentic Design Patterns
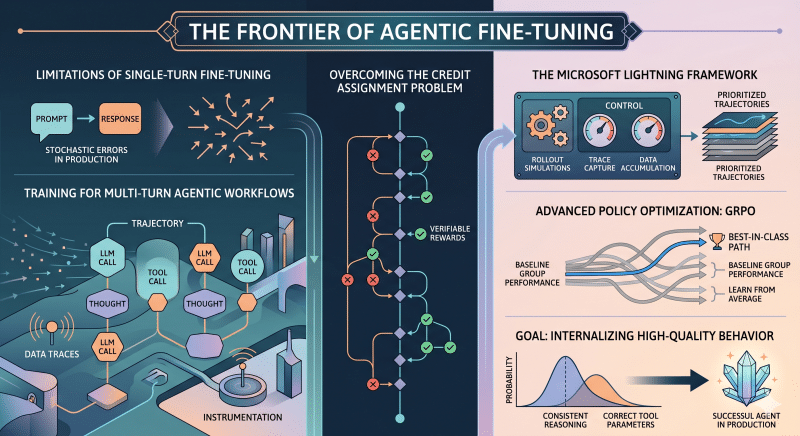
Focus
Moving beyond baseline RAG into multi-hop, exploratory search handled by agents, and shifting fine-tuning paradigms toward multi-turn, trajectory-based “Agentic Training.”
Key Takeaways
- Agentic RAG: Overcoming single-vector limitations, query decomposition, hypothetical document embeddings (HyDE), and multi-source routing.
- Judgment vs. Retrieval: Conversational memory, grounding, system guardrails, and epistemic humility.
- Agentic Training Hypothesis: The shift from single-turn SFT/RLHF to multi-turn rollouts and trajectory-based training.
- Framework Implementation: Solving the sequential credit assignment problem using Microsoft’s Agent Lightning framework.
Lab
- Agentic RAG implementation
- Agentic Training using Agent Lightning
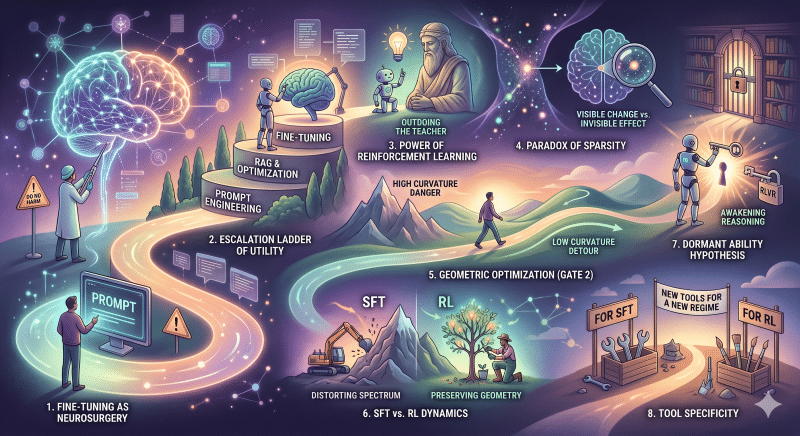
Focus
A capstone look at the future of model adaptation, evaluating the enduring relevance of fine-tuning, the mechanics of Reinforcement Learning with Verifiable Rewards (RLVR), and scaling pre-training infrastructure.
Key Takeaways
- The Escalation Ladder: Evaluating RAG vs. Fine-tuning and the tactical decisions for production deployment.
- Mechanics of RLVR: The three-gate theory (KL Anchor, Model Geometry, Precision) and the breaking of the Manifold Hypothesis.
- Geometry of Parameter Space: The conservation of probability, superposition, and the limitations of principal-aligned adapters.
Lab
- Evaluation of fine-tuned models
- MARL (Multi-Agent Reinforcement Learning)
In-Person vs Remote Participation
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago


