Course Overview
Starting: TBD
In today’s rapidly evolving enterprise landscape, mastering the art of LLM (Large Language Model) fine-tuning has become indispensable for engineers seeking to enhance the performance and specificity of AI models. This course is meticulously designed to provide you with the practical skills and theoretical knowledge required to excel in fine-tuning LLMs, ensuring that your models not only perform optimally but also maintain robustness and accuracy across diverse applications.
You can attend the course in person or remotely. State-of-the-art facilities and instructional equipment ensure that the learning experience is invariant of either choice. Of course, you can also mix the two modes: attend the course in person when you can, and attend it remotely when you cannot. All sessions are live-streamed and recorded and available on the course portal.
Learning Outcome
You will acquire a strong understanding of fine-tuning techniques and their applications, enhancing your ability to adapt pre-trained models to specific tasks effectively.
Schedule
| START DATE | TBD |
|---|---|
| Periodicity | Meets every Monday and Wednesday evening. |
| Schedule | 7 PM to 10 PM PST |
| Lectures | Monday evening sessions |
| Labs | Wednesday evening sessions |
| End Date | Monday, May 26th, 2025 |
Call us at 1.855.LEARN.AI for more information.
Skills You Will Learn
Model Fine-Tuning, Prompt Engineering, Advanced AI Optimization Techniques, Evaluation Metrics for Model Performance
Prerequisites
Syllabus details
 This 2-month intensive course is predominantly hands-on, featuring extensive lab exercises, projects, quizzes, and case studies. It focuses on contemporary fine-tuning techniques that go beyond simply feeding more data into an LLM. We delve into sophisticated methods that prevent catastrophic forgetting and reduce hallucinations while achieving measurable improvements in domain-specific tasks.
This 2-month intensive course is predominantly hands-on, featuring extensive lab exercises, projects, quizzes, and case studies. It focuses on contemporary fine-tuning techniques that go beyond simply feeding more data into an LLM. We delve into sophisticated methods that prevent catastrophic forgetting and reduce hallucinations while achieving measurable improvements in domain-specific tasks. The following topics will be covered:
The following topics will be covered:
-
Efficiency of Fine-Tuning:
Learn how fine-tuning adapts pre-trained models using minimal data and computation, ideal for real-world scenarios with limited labeled data.
-
Foundational Models and Transfer Learning:
Understand how large pre-trained models, like those from ImageNet, can be fine-tuned for specific tasks with smaller datasets.
-
Neural Scaling Laws:
Explore the relationship between model size, data requirements, and computational needs for achieving optimal performance.

In this guided lab session, the following topics will be covered:
-
Text and Image Classification:
Fine-tuning techniques for classification tasks across text and image domains.
-
Step-by-Step Walkthrough:
Guided setup for preparing environments and executing fine-tuning workflows.
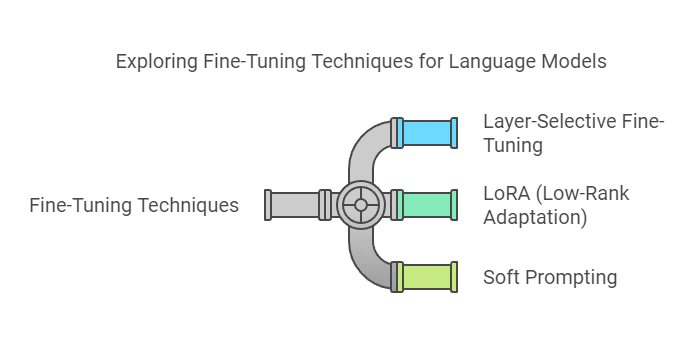
In this session, we will cover the following topics:
-
Fine-Tuning Techniques for Large Language Models:
Practical and efficient methods like Layer-Selective Fine-Tuning, LoRA, and Soft Prompting for adapting LLMs to domain-specific tasks cost-effectively.
-
Mathematics of Self-Attention in Transformers:
A detailed look at the self-attention mechanism, focusing on query-key alignment and transformation matrices to enhance flexibility and optimize attention weights.

In this guided lab session, the following topics will be covered:
-
Vision Transformers (ViTs):
Fine-tuning ViTs using the “Trees” dataset with patch-based segmentation and Hugging Face’s ViT Image Processor.
-
Transfer Learning vs. Full Fine-Tuning:
Comparing updating only classification layers with adjusting all parameters for datasets of varying similarity.
-
Parameter-Efficient Fine-Tuning:
Applying LoRA and PEFT techniques for low-resource scenarios, reducing model size by saving only adapter layers.
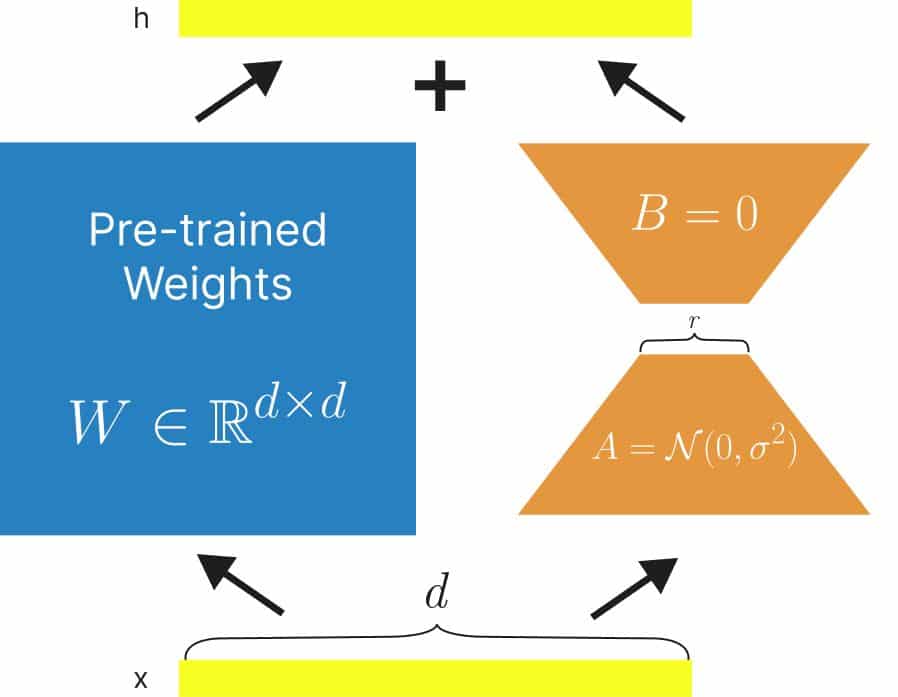
In this session, the following topics will be covered:
Diving deeper into Low-Rank Adaptation (LoRA)
- We will examine the mathematical foundation behind LoRA, understanding how it reduces the number of trainable parameters and lowers computational requirements. The session will also cover practical applications, showcasing its effectiveness in domain-specific fine-tuning tasks, particularly for tasks with limited labeled data.
- Go through a recent conference related to Gen-AI for a deeper understanding.
-
Synthetic Data Significance:
Addressing class imbalance and data scarcity while enhancing model robustness and generalization.
-
Advanced Data Augmentation:
Utilizing techniques like GANs, diffusion models, and flow models to create realistic, use-case-specific synthetic data.
-
Parameter-Efficient Fine-Tuning:
Exploring resource-efficient methods like LoRA and TokenForm for effective fine-tuning with minimal computational costs.
-
Model Soup Approach:
Improving performance by averaging parameters from fine-tuned models, with emphasis on careful implementation.
-
Bias and Compliance:
Ensuring synthetic data maintains ethical standards by avoiding bias and adhering to privacy regulations.
-
Objective:
Fine-tuning sentence transformers by adjusting embedding vectors to group similar sentences closer, improving their suitability for downstream tasks.
-
Data Preparation:
Organizing sentences by subject into labeled pairs to help the model learn relationships between similar and dissimilar subjects.
-
Training Strategy:
Fine-tuning using cosine similarity as a loss function, bringing embeddings of similar sentences closer in vector space.
-
Evaluation and Results:
Measuring effectiveness by comparing similarity scores pre- and post-tuning, improving subject separation accuracy from 80% to 98%.
-
Dimensionality Robustness:
Reducing embedding dimensions to as low as 2 with minimal performance loss, showcasing embedding robustness for simpler tasks like three-class separation.
-
Custom Data Fine-Tuning:
Fine-tuning Chronos for time-series tasks like electricity load forecasting using segmented data in Arrow format to improve accuracy.
-
LoRA vs. Full Fine-Tuning:
Compare LoRA’s efficient, storage-saving approach to full fine-tuning, highlighting performance and memory trade-offs.
-
Configuration and Paths:
Ensure correct file paths in configurations to prevent errors during model training and checkpoint loading.
-
Environment Variability:
Address errors arising from differences between environments like Mac and Linux using consistent virtual setups.
-
Performance Metrics:
Evaluate models using metrics like MASE to compare LoRA-based and fully fine-tuned models.

In this lab session, the following topics will be covered:
-
Fine-tuning methods like LoRA and Unsloth for GPT and Mistral models:
Learn how to apply efficient fine-tuning techniques like LoRA and Unsloth to GPT and Mistral models.
-
Using perplexity to evaluate text generation improvements:
Explore how perplexity is used as a metric to measure improvements in text generation quality.

In this guided lab session, we will cover the following topics:
-
Text-to-SQL Fine-Tuning:
Train the Mistral 7B model using LoRA with a dataset of questions, context, and answers to improve SQL generation accuracy.
-
PromptGuard Security:
Explore PromptGuard for detecting and classifying safe, suspicious, and malicious prompts against adversarial attacks.
-
Hardware Optimization:
Address training challenges with large models using GPUs (25 GB VRAM) and apply quantization for training on consumer-grade GPUs.
-
Cloud Training Solutions:
Utilize platforms like Modal with free credits for resource-constrained model experiments.
-
Token Management & Optimization:
Configure Hugging Face tokens and apply fine-tuning techniques like data augmentation and parameter adjustments for enhanced performance.
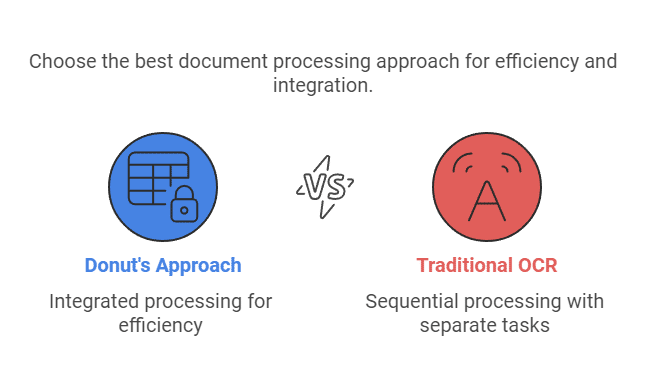
In this guided lab session, we will cover the following topics:
-
Donut Workflow Overview:
Explore Donut’s pipeline for document understanding tasks.
-
Dataset Preparation:
Learn to encode ground truth data as tagged sequences (e.g., XML-like) and resize images for model compatibility.
-
Model Customization:
Add special tokens, resize embeddings, and configure the decoder for specific document layouts and formats.
-
Training and Deployment:
Fine-tune Donut for tasks like invoice parsing and utilize Hugging Face Hub for model storage and deployment.
-
Performance Evaluation:
Assess predictions using field accuracy and BLEU scores to identify areas for improvement.

In this guided lab session, we will cover the following topics:
-
Diffusion Models and Fine-Tuning:
Understand the noising-denoising process in diffusion models for generative tasks like image creation. Fine-tune models using LoRA to enhance efficiency, comparing pre-trained, LoRA fine-tuned, and fully fine-tuned models.
-
Hands-On Experimentation:
Test prompts (e.g., “red-colored sunflower”) to observe the impact of fine-tuning on image generation. Explore platforms like Modal and RunPod for model execution and tools like Hugging Face’s BitsAndBytes for quantization.
-
Key Insights and Next Steps:
Learn trade-offs between computational cost and performance, with LoRA offering an efficient balance. Preview future sessions on advanced fine-tuning and leveraging pre-quantized models.

In this guided lab session, we will cover the following topics:
-
Cloud-Based Model Training:
Use Modal to run tasks like sentiment analysis with DistilBERT, emphasizing simplicity and cost-effectiveness compared to platforms like AWS and GCP.
-
Synthetic Data Generation:
Work with tools like Mostly AI, Gretel AI, and SDV to create secure synthetic tabular and text datasets, focusing on privacy and realistic data generation.
-
Workflow Customization:
Set up environments, adapt scripts for cloud platforms, and debug pipelines to ensure seamless execution.
-
Evaluation Metrics:
Validate synthetic data quality using metrics like accuracy and precision, and compare distributions with real datasets.
-
Applications and Production:
Explore how synthetic data overcomes sensitive data challenges, aids preprocessing for robust workflows, and supports efficient LLM deployment in production.
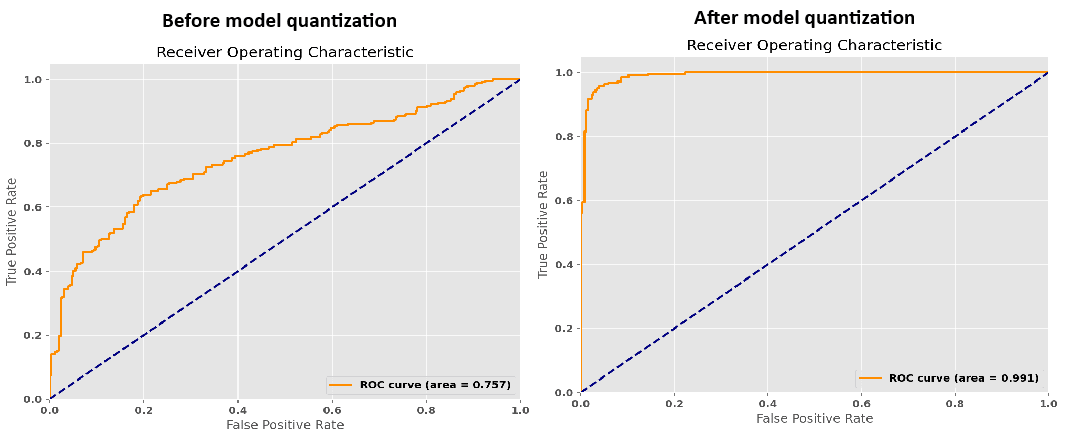
In this guided lab session, we will cover the following topics:
-
Fine-Tuning for Domain-Specific Applications:
Train models tailored to specialized fields like medical assistance, ensuring accurate and relevant outputs using structured templates and aligned datasets.
-
Quantization for Efficiency:
Optimize model performance with quantization techniques, reducing resource usage while maintaining accuracy, especially for tasks like sequence classification.
-
Training and Evaluation:
Fine-tune Llama models by adjusting parameters and evaluate their performance, with a focus on leveraging tools like UnSLoT for enhanced results.
Teaching Faculty

Asif Qamar
Chief Scientist and Educator
Background
Over more than three decades, Asif’s career has spanned two parallel tracks: as a deeply technical architect & vice president and as a passionate educator. While he primarily spends his time technically leading research and development efforts, he finds expression for his love of teaching in the courses he offers. Through this, he aims to mentor and cultivate the next generation of great AI leaders, engineers, data scientists & technical craftsmen.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last 32 years. He has taught at the University of California, Berkeley extension, the University of Illinois, Urbana-Champaign (UIUC), and Syracuse University. He has also given a large number of courses, seminars, and talks at technical workplaces. He has been honored with various excellence in teaching awards in universities and technical workplaces.

Chandar Lakshminarayan
Head of AI Engineering
Background
A career spanning 25+ years in fundamental and applied research, application development and maintenance, service delivery management and product development. Passionate about building products that leverage AI/ML. This has been the focus of his work for the last decade. He also has a background in computer vision for industry manufacturing, where he innovated many novel algorithms for high precision measurements of engineering components. Furthermore, he has done innovative algorithmic work in robotics, motion control and CNC.
Educator
He has also been an educator, teaching various subjects in AI/machine learning, computer science, and Physics for the last decade.
Teaching Assistants
Our teaching assistants will guide you through your labs and projects. Whenever you need help or clarification, contact them on the SupportVectors Discord server or set up a Zoom meeting.

Kate Amon
Univ. of California, Berkeley

Shubeeksh K
MS Ramaiah Institute of Technology

Purnendu Prabhat
Kalasalingam Univ.

Harini Datla
Indian Statistical Institute

Kunal Lall
Univ. of Illinois, Chicago
In-Person vs Remote Participation

Plutarch
Education is not the filling of a pail, but the lighting of a fire. “For the mind does not require filling like a bottle, but rather, like wood, it only requires kindling to create in it an impulse to think independently and an ardent desire for the truth.
Our Goal: build the next generation of data scientists and AI engineers
The AI revolution is perhaps the most transformative period in our world. As data science and AI increasingly permeate the fabric of our lives, there arises a need for deeply trained scientists and engineers who can be a part of the revolution.
Over 2250+ AI engineers and data scientists trained
- Instructors with over three decades of teaching excellence and experience at leading universities.
- Deeply technical architects and AI engineers with a track record of excellence.
- More than 30 workshops and courses are offered
- This is a state-of-the-art facility with over a thousand square feet of white-boarding space and over ten student discussion rooms, each equipped with state-of-the-art audio-video.
- 20+ research internships finished.
Where technical excellence meets a passion for teaching
There is no dearth of technical genius in the world; likewise, many are willing and engaged in teaching. However, it is relatively rare to find someone who has years of technical excellence, proven leadership in the field, and who is also a passionate and well-loved teacher.
SupportVectors is a gathering of such technical minds whose courses are a crucible for in-depth technical mastery in this very exciting field of AI and data science.
A personalized learning experience to motivate and inspire you
Our teaching faculty will work closely with you to help you make progress through the courses. Besides the lecture sessions and lab work, we provide unlimited one-on-one sessions to the course participants, community discussion groups, a social learning environment in our state-of-the-art facility, career guidance, interview preparation, and access to our network of SupportVectors alumni.
Join over 2000 professionals who have developed expertise in AI/ML
Become Part of SupportVectors to Inculcate In-depth Technical Abilities and Further Your Career.


